
分布式系统 - partitioning
上一篇文章说了分布式系统的复制(replication)技术。这一篇来说说分区(partitioning)。
replication解决了availability。partitioning解决scalability。
复制技术的思路是:在集群内制造更多的相同状态的节点承担流量,这时每个节点都保存所有记录。但如果data set不停的增长,导致一个节点无法完全保存所有数据,就需要partitioning:将数据break down,使每个节点只需要保存特定范围的记录,对单条记录的流量最终只会落到特定的节点内,从而达到高扩展性。
分区的技术通常要考虑几个问题:
- 该怎么对数据进行分区?比如我要将整个data set部署到10个节点,怎么决定记录A应该落在节点1还是节点2?
- Rebalancing。
- 请求路由(Request routing)。
Partitioning by…
该怎么对数据进行分区?这个问题该考虑的是两点:
- 尽可能均匀分布,避免数据热点问题。
- 让rebalance操作尽可能方便,代价尽可能小。
下面,以常见的以int型主键id作为分区因子,看看几个对数据进行分区的策略。
Partitioning by Key Range
第一个方法是:每个partition存储一段(id)连续范围的数据。如:id为(0, 1000]的数据落在节点1,id为(1001, 2001]的数据落在节点2。
这一策略的一个好处是:对id进行范围查询很容易。在存储的上层可以通过分析query判断该到哪个节点寻找数据。
比如,考虑一个场景:有一个记录室内温度的应用,它每一秒会将当前温度写入数据库。id使用时间格式(year-month-day-hour-minute-second)。而大部分读取场景都是需要读取某一天内的温度变化。
这样的场景适合用上面的分区做partition。因为它使得时间相近的两条记录很有可能在同一分片。在查询的时候只需要查一个分片,就可以把一段连续时间的数据拿出来。也就是说,key range做的sharding使primary key range query(如:where id in (1, 1000))变得很容易实现。
然而,采用这样的分区策略会同样让写入操作成为热点。在写入场景下,所有流量都会落到同一分片,sharding几乎没有起任何作用。
Partitioning by Hash of Key
在真实的workload下,很少使用range作为sharding的策略。一般是使用一种更随机的方法:散列(hash)。
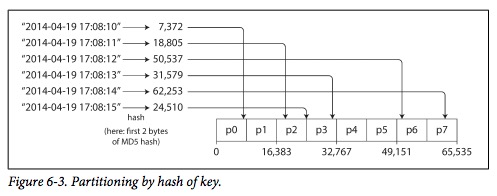
将作为sharding依据的key(如id)求hash,然后根据得出的hash值决定这条记录应该落在哪个分片上。这样的技术能有效的让数据更随机的落到不同分片。一种hash的变种是一致性哈希。它的目的是在rebalance的时候,让数据和节点的mapping关系尽可能保持一致。
采用hash作为sharding策略的问题也显而易见:primary key range query变得艰难。一句key range的query必须要发送到所有的分片,才能得到准确的答案,这显然是违背高可用原则的。所以,在一些分布式数据库下,并不支持这类查询。
Rebalance
Rebalancing的意思和rehash相近,是:重新决定数据和节点的mapping关系,移动数据到新的位置。有这些情况需要执行rebalancing:
- 数据膨胀,需要更多节点。
- 线上环境,负责一个分片的节点故障且不能failover。
对于rebalance操作本身,有几个最低要求:
- rebalance之后,数据应该尽可能平均的分布在各个分片。
- rebalance过程中,集群仍能正确处理读写请求。
- 让尽可能多的数据留在原来的分片。最小化网络和磁盘IO。
下面介绍各种rebalance策略。
不要使用 hash mod N
上图展示hash key策略的图中,可以看到它的策略是,根据求出的hash值,看这个hash值属于哪个范围,决定落在哪个节点。
为什么不是简单的用hash值取余(mod)节点总数呢?
这是因为用取余的方法,当节点数改变的时候, 大部分的数据的分片位置都会失效,都需要移动。这违背第三点的要求。
Fixed number of partitions
一个很巧妙的方法是:固定分片数且让分片数大于节点数,让分片数和节点数解耦。例如:一个有10个节点的数据库集群,它们可以分成1000个节点,那么,一个节点会分到大约100个分片的数据。
当新增一个节点时,这时集群的节点总数是10 + 1 = 11个,每个节点分到的分片数应该是1000 / 11 = 90个。怎样达到平衡又让尽可能多的数据留在原来的分片呢?新节点会从原有的各个节点里平均的偷取分片组成自己的分片,如图:
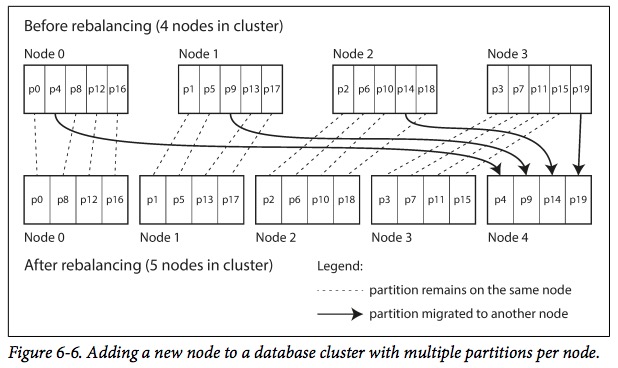
减少节点的过程与之类似。
这个方法的思想是:整个过程中,总的分片没有改变,数据和分片的mapping关系也没有改变,改变的是 分片和节点的mapping关系。
这个方法中,分片数是在建库的时候决定的,并在之后不能改变。分片数的选择变得很重要,太大或者太小都会有性能问题。
Request Routing
Request routing不仅是由于分区带来的问题,而是分布式系统里需要解决的多节点通信的问题。之前已经写过文章讨论,可看:分布式系统 - 服务治理。
参考
- 《Designing Data-Intensive Applications》