
分布式系统case by case - redis的分布式方案
经常有一些面试题喜欢让人设计一个分布式存储系统,其目的是面试者对分布式系统的常见知识的掌握和运用。这篇文章来讨论下这个问题,从redis的实现说起,看看一个分布式系统高可用的方案有哪些。
之前已经说过对一个系统做分布式化,目的是三个:
- scalability
- availability
- performance
要达到这两点目的,一个有状态的系统要做分布式集群化,必然会做的是两点措施:1. replication,2. sharding。这两个实施之后,会引入新的问题:1. 一致性问题(一致性问题又可以分为两个问题:1.1. 分布式处理后,redis集群可以提供什么程度的一致性保证?1.2. 分布式处理后,会新增什么不一致的情况呢?),2. 集群无时无刻有节点不可用。另外分布式化是为了让集群即使在故障的时候依然可用,那么又涉及几个问题:1. 故障检测,2. 故障转移,3. 故障恢复……
我们会根据这个思路,一直提问,并从redis里找到相关的解决方案,还会看看其他的解决方案。
master-slave replication
对于有状态的分布式系统来说,要提高系统的可用性,冗余是必须考虑的最基本的方法,而最简单最常用的冗余方法,就是复制。
redis的复制机制是master-slave模型 - 对同一份数据,会有多份拷贝分布在多个节点,其中,只有一个master节点可以更新,master节点更新后,会通过一定机制使其它节点同步状态。在redis官方文档中,复制系统是通过三个机制实现:
- 在正常状态下,master会将接收到的指令传播到slave节点,使slave节点的状态同步。
- 当从节点发生故障,将有一段时间不可用。当从节点恢复时,会发起partial resynchronization请求,请求这段时间内,master节点执行了的所有指令,重新执行一遍,这时这个slave节点的状态又会再次同步。
- 当partial resynchronization不可用时,从节点会发起full resynchronization,请求完整的同步。完成之后,进入正常状态,主从之间通过指令流同步。
整个机制里,值得注意的是两点:
- 在指令传播的同步场景里,是异步复制(asynchronous replication)的。
- partial resynchronization和full resynchronization的同步场景中,master节点是非阻塞的。
指令传播的实现
指令传播是通过在主从节点共同维护偏移量实现的。从节点会通过每秒向主节点发送命令的方式保持心跳,命令包括:
- Replication ID - 主节点的id(集群内唯一)。
- offset - 从节点已经处理了指令字节偏移量。
主节点会将最近执行的指令放入一个buffer中,同时维护自己已经执行的指令偏移量。从节点通过心跳的方式告诉主节点,已经执行的指令偏移量。主节点通过比较两者的差距,在buffer里偏移量差值的指令字节发送给从节点。

Sentinel
上一节中已经介绍了redis的复制方案。实现了复制之后,集群不是马上就能获得高可用的好处,我们还需要一套对集群状态的维护,检测,failover的机制。redis里使用哨兵(sentiel)解决这一问题。
sentinel的实现方法是在集群中有一组特殊功能的节点,它们负责维护集群的健康度。官方文档中,Sentinel提供这几点功能:
Monitoring. Sentinel constantly checks if your master and slave instances are working as expected.
Notification. Sentinel can notify the system administrator, another computer programs, via an API, that something is wrong with one of the monitored Redis instances.
Automatic failover. If a master is not working as expected, Sentinel can start a failover process where a slave is promoted to master, the other additional slaves are reconfigured to use the new master, and the applications using the Redis server informed about the new address to use when connecting.
Configuration provider. Sentinel acts as a source of authority for clients service discovery: clients connect to Sentinels in order to ask for the address of the current Redis master responsible for a given service. If a failover occurs, Sentinels will report the new address.
简而言之,sentinel最大作用是自动故障转移。
Redis Sentinel 本身也是一个分布式系统(否则将成为单点),它要求至少三个节点。它的架构图是这样:
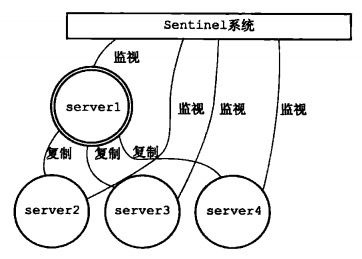
下面来看看它是怎么工作的:
- 和master节点创建连接。sentinel集群上线后,会与集群内的master节点创建命令连接和订阅连接。
- 定期轮询master节点和slave节点信息。sentinel默认会以10s一次的频率,通过命令连接向master节点和slave节点发送INFO命令。master和slave会将彼此的一些信息汇报给sentinel,通过这样的轮询,sentinel可以知道集群内master和slave的拓扑结构,具体物理地址(IP),连接情况,从服务器的复制偏移量,等等。
- sentinel主动向master节点和slave节点推送信息。sentinel会以2s一次的频率,通过命令连接向master节点和slave节点发送PUBLISH指令,主要是为了心跳检测,另外汇报sentinel节点本身的物理地址,和master节点的物理地址。
- 保持心跳。所有有命令连接的节点间会有心跳,下详。
- sentinel集群内部自治。sentinel集群内部不需要复杂的心跳方式,它们彼此之间的发现是通过上面2完成的(sentinel轮询master时,master会报告与它相连的所有sentinel节点),然后在彼此间建立连接可以通信。
通过这样的方式,sentinel可以监视(Monitoring)集群内的master节点健康状况。为failure detection和failover做基础。下详。
failure detection
要实现故障转移,首先要有故障检测的能力。故障检测中,最怕是错把一些网络抖动当成的节点不可用,导致错误地执行了failover。这里看看redis sentinel的检测方案。
sentinel的failure detection分为两步,主观下线状态和客观下线状态。
-
主观下线:首先是保持心跳。每个sentinel节点默认会以1s一次的频率向所有与它创建了命令连接的节点发送PING命令。当master节点连续N毫秒(N可配置)没有返回有效回复时,这个sentinel节点会认为master节点已经下线。
-
客观下线:当sentinel节点将一个master节点判断为下线后,为了确认这个master节点是否真的下线,它会向同样监视这一master节点的其他sentinel节点询问,当足够多的sentinel节点(可配置,默认为 大于 n / 2)判断下线,sentinel节点会将这个master节点判定为客观下线。并进行故障转移。
automatical failover
故障转移简单来说就是sentinel节点告诉一个slave节点,让它来成为master节点。但首先需要解决的问题是:sentinel要选举一个leader执行failover。这一点如果处理不好,那么将有多个sentinel节点执行failover流程,导致多个master出现,产生split brain的问题。
Sentinel采用了Raft协议实现了Sentinel间选举Leader的算法,不过也不完全跟论文描述的步骤一致。在这里不赘述。
执行failover的流程可分为这几步:
- 从现有的slave中挑选出新的master。
- 让其他的slave的复制目标改为新的master。
- 将已下线的master设置为slave。(试想如果没有这一步,那么当这个master recover后,仍然认为自己是master节点,将会产生严重的crash。)
这些动作通过sentinel和其他节点之间的指令即可实现。
redis cluster
相比起接下来要说的cluster solution,sentinel是一个朴素的提供HA的手段,它只管failover,也就是它只能处理一种crash failure。当要考虑更多的容错时,redis提供更严谨的分布式方案 - redis cluster。
在redis cluster模式下,拓扑结构是去中心化的网状结构。在一个有N个节点的集群中,每个节点都与其余的N-1个节点相连。点对点的通信使用一个叫Cluster Bus的内部协议。
redis cluster模式下,任意两个节点会保持通信,交互以下信息:
- 节点的 IP 地址和 TCP 端口号。
- 各种标识。
- 节点使用的哈希槽。
- 最近一次用集群连接发送 ping 包的时间。
- 最近一次在回复中收到一个 pong 包的时间。
- 最近一次标识节点失效的时间。
- 该节点的从节点个数。
- 如果该节点是从节点,会有主节点ID信息。(如果它是个主节点则该信息置为0000000…)
集群模式下的redis,如果提高整个集群的可用性?它提供这几个功能:
- 基于槽的sharding。
- fail detection & master failover(与sentinel类似)
- 集群内部的指令重定向。(当一个节点无法处理一个指令时,它可以代理到其它节点,而client不感知)
- replica migration
集群化后带来的一致性问题
redis cluster的分布式方案也满足CAP规律,在使用后,redis不能提供强一致的保证。
最基本的一个导致不能提供强一致的原因是它使用异步复制(asynchronous replication)。也就是指令执行返回时,不保证从库的状态和主库一致。
另一个会导致写入丢失的场景发生在网络分区时(network partition)。
举个例子,假设集群包含A,B,C,A1,B1,C1 六个节点,其中 A,B,C 为主节点,A1,B1,C1为A,B,C的从节点,还有一个客户端 Z1。
假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点A,C,A1,B1 和 C1,小部分的一方则包含节点 B 和客户端 Z1。
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了。
参考
- 《分布式缓存 - 从原理到实践》
- 《redis设计与实现(第二版)》
- 《redis开发与运维》
- https://redis.io/topics/introduction
- https://stackoverflow.com/questions/31143072/redis-sentinel-vs-clustering
- http://weizijun.cn/2015/04/30/redis%20sentinel%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/