
分布式系统 - 批处理与MapReduce
在分布式系统或单机系统中,对数据的处理分别有两种常见手段,是批处理(batch processing)和流处理(stream processing)。 区别于流处理,批处理的手段处理数据会有这几个特点和隐含的假设:
- 处理过程中,不能和终端用户交互(区别于交互式的处理)
- 数据量大,而且是冷数据,或称离线数据(就是处理过程中,数据状态不变或可忽略)
- 处理速度慢,且结果在完全处理完之后才可见
而MapReduce是google在2004年以论文方式推出的提供分布式批处理实现的框架的编程(抽象)模型。MapReduce在工业上的实现有很多,Hadoop是其中一个开源的实现版本。
单机MapReduce
MapReduce的编程框架将大数据处理的“石器时代”带入“青铜时代”。它提供给使用者的抽象是两个所有人再熟悉不过的fp范式的函数:map(映射)和reduce(规约)。在学习分布式MapReduce框架之前,我们先实现一个单机版的MapReduce,回忆一下这两个简单有力的抽象,能做什么事情。
以最简单的“word count”统计这个use case入手。假设需要统计文件系统里某几个文本文件中,所有出现过的单词,和它们出现的次数。你会怎么做呢?用MapReduce的模型实现,则是两步:
- map函数,读取文件,统计这个文件出现的单词word,每次出现,记录一条记录,输出一个list<word, count>。
- reduce函数,入参是一个key和这个key下所有的value(<word, list
>),对所有value求和,最终输出所有total sum(<word, sum>)。
用简单的代码实现一下,这个算法是非常简单的:
const fs = require('fs')
class KeyValue {
constructor(key, value) {
this.key = key
this.value = value
}
}
const mapF = (fileName, contents) =>
contents.split(/[^A-Za-z]/).filter(a => a.length > 0).map((word) => new KeyValue(word, 1))
const reduceF = (key, values) => {return {[key]: values.reduce((sum, v) => sum + v)}}
const sort = (a, b) => {
if (a.key < b.key) {
return -1;
} else if (a.key > b.key) {
return 1;
} else {
return 0;
}
}
const start = () => {
// './contents/pg*.txt'
["./contents/pg-being_ernest.txt", "./contents/pg-dorian_gray.txt", "./contents/pg-frankenstein.txt"]
// map
let intermediate = []
fileNames.forEach((name, _) => {
contents = fs.readFileSync(name, 'utf8');
const results = mapF(name, contents)
intermediate.push.apply(intermediate, results)
});
// shuffle
intermediate.sort(sort)
// reduce
let i = 0
let results = []
while (i < intermediate.length) {
let j = i
let values = []
while (j < intermediate.length && intermediate[i].key == intermediate[j].key) {
values.push(intermediate[j].value)
j = j + 1
}
const reduceResult = reduceF(intermediate[i].key, values)
results.push(reduceResult)
i = j
}
console.log(results);
}
start()
你可以认为上文中的整个执行流程就是单机版MapReduce的框架,调用方如果需要使用,需要实现两个函数:mapF,reduceF,去完成不同的任务。整个执行流程如图:
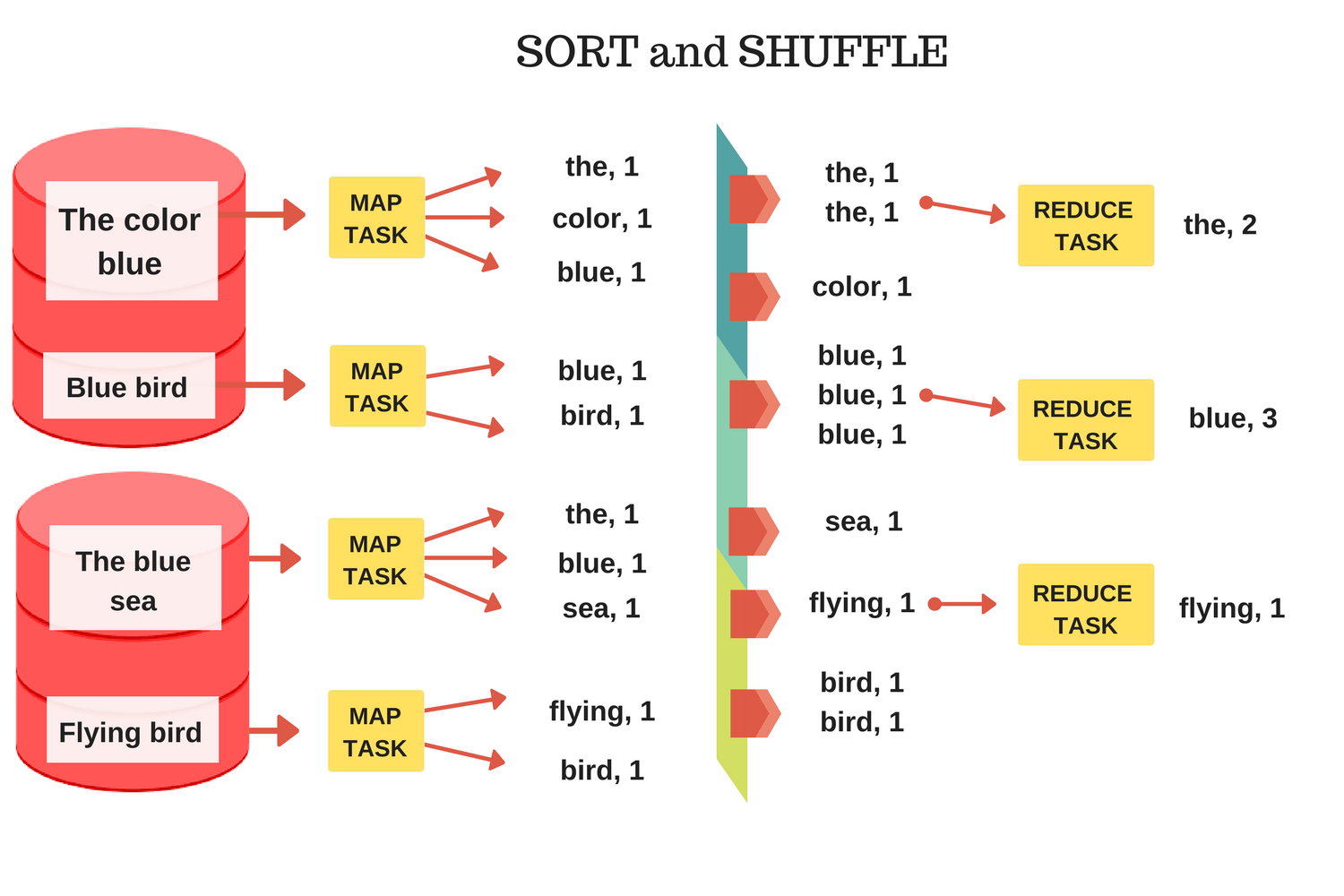
在单机场景中,一切都好像很简单,然后呢?
设计分布式MapReduce
当从单机变成分布式环境后,情况将会变得复杂得多。整个分布式MapReduce框架的魅力在于,它屏蔽了分布式系统运算和存储中棘手的问题(fault tolerance, reliability, synchronization,availability),提供简单优雅的抽象。在上层使用者的视角,还是只需要实现简单的map函数和reduce函数,由整个mapReduce框架保证批处理流程正确执行。
我尝试根据google的mapreduce论文和MIT的6.824课程的go语言的mapreduce框架,实现一个简单的分布式mapreduce系统,看看要处理哪些问题。
整体架构
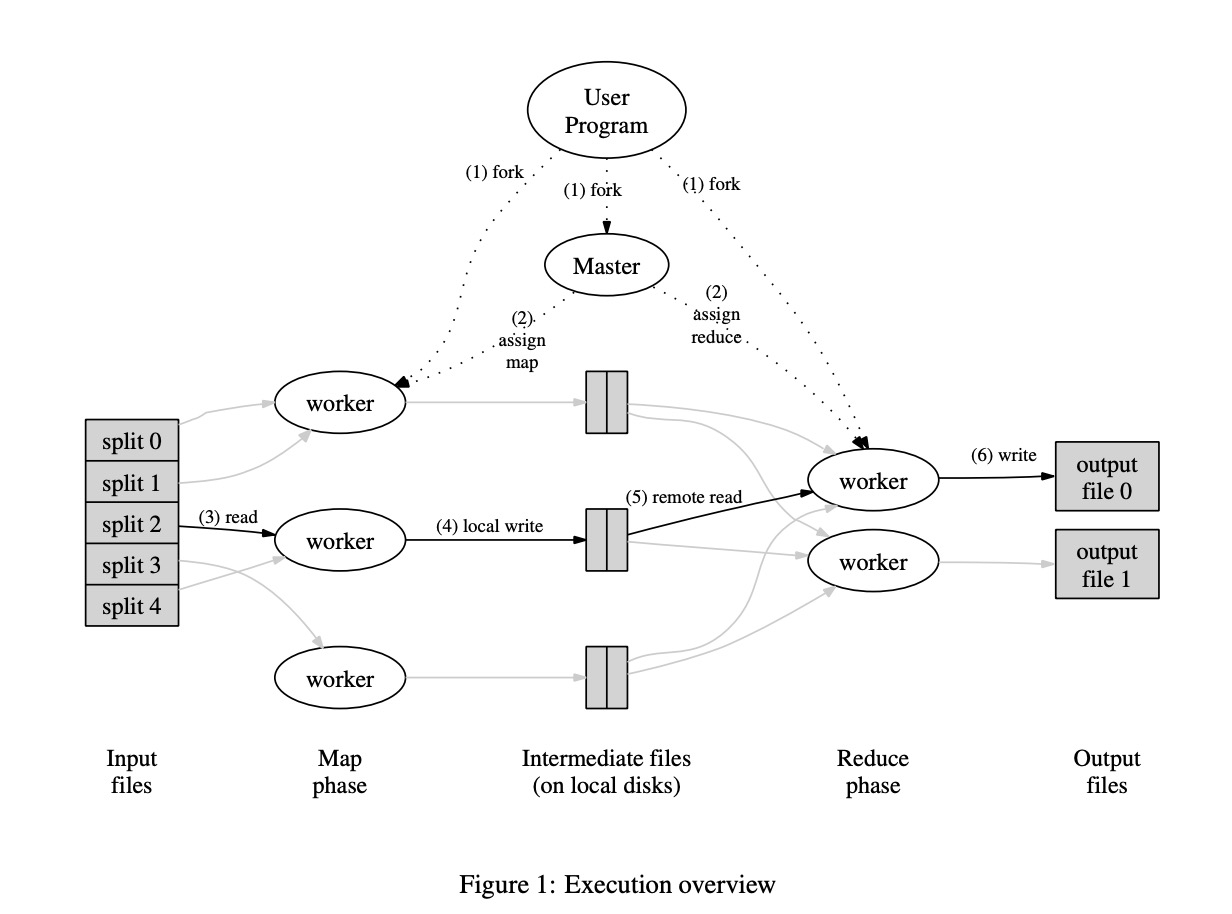
根据google原版论文的描述,整个系统架构如图,采用的是master-worker架构,有几个点:
- 整个集群有两类节点,master node和worker node。
- master节点保存整个mapreduce job的状态,同时负责调度所有的worker节点;
- worker节点本身无状态,当启动一个worker节点时,它轮询地向主节点不断获取一个任务(task),有可能是map或者是reduce,获取后执行,执行成功后向报告给master,由master节点记录。
- 用户和集群通信只通过主节点,worker节点不能直接访问。
一个核心的设计点在于单主和worker无状态化。集群状态只保存在主节点上,避免了各种一致性问题;虽然有单点问题,但主节点的work load很低(主要的负载都在worker节点),master挂掉的几率很小。同时,这样设计简化了主从间通信的复杂度(master和worker之间只要极少量语义的接口就可以完成协作)。
worker无状态化同时带来了扩展性:可以很方便的通过增加worker机器scale out,不需要担心各种复制,分片问题。
当然,single master还是会有单点问题,具体的容错保障机制在下文中会提及。
状态机设计
一个mapreduce job的状态由主节点记录,主节点记录整个job的状态并记录每一个task的状态,当worker请求一个task时,主节点根据这几个状态分配一个合适的任务给worker。
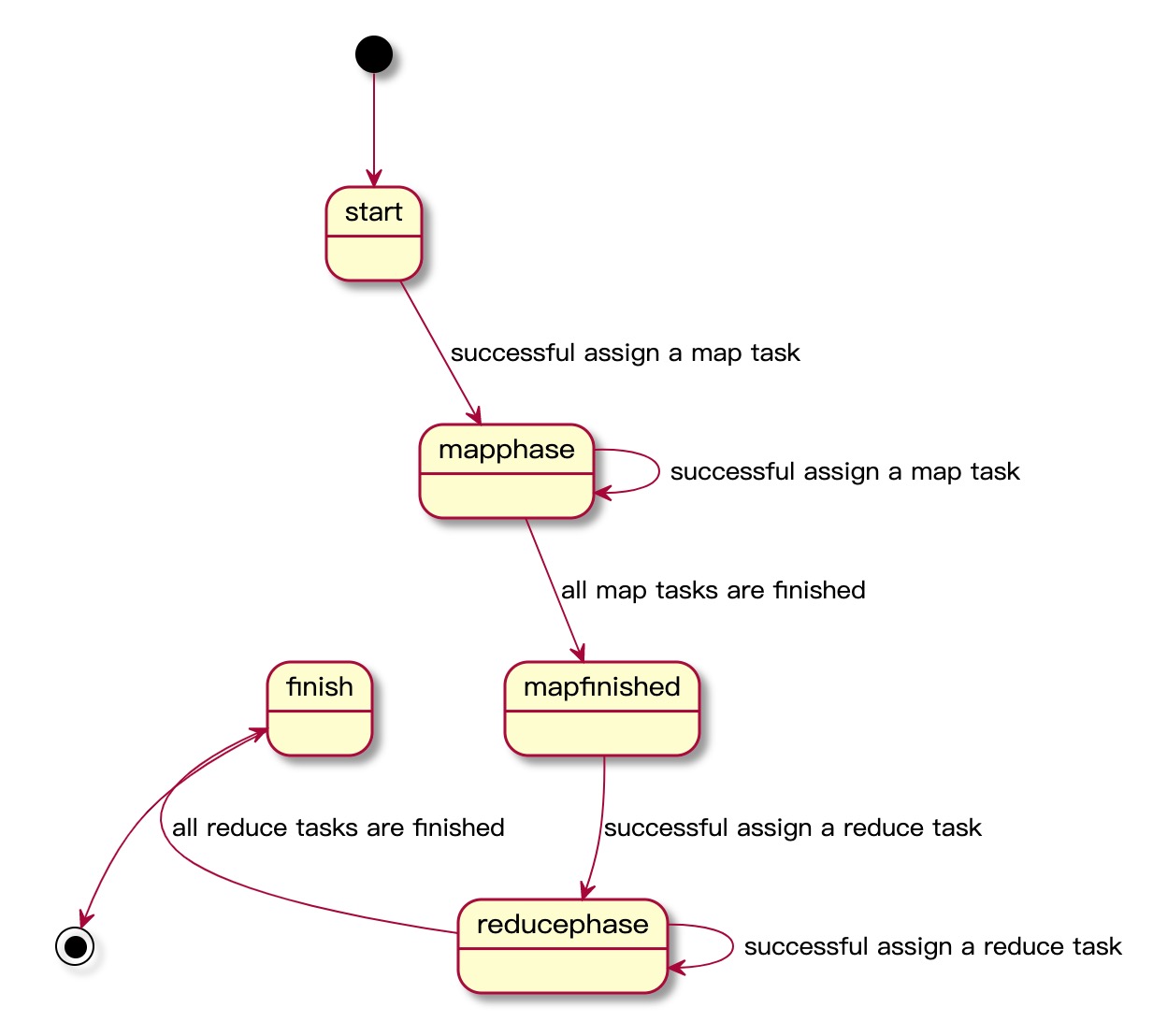
状态机设计是关键一步,因为worker节点有可能由于各种各样的原因导致执行失败,甚至执行成功但没有报告给master。这时依赖master壮健的状态机推进来实现整个job的容错。根据论文的描述,我在实现时,使用的状态机如下:
一个mapreduce任务一共有5种状态:
- start:开始,待请求
- map phase:在执行map任务阶段
- map finished:map任务已执行完成,待执行reduce任务
- reduce phase:正在执行reduce任务
- finish:完成
状态机如图:
worker节点也有状态机,是节点内部执行一个task的状态,这个状态比较简单:idle,in-progress,completed。同时,因为task是由master节点下发,所以master节点也会维护所有task的状态。
master和worker之间的通信协议设计
由于上文提及的整体架构的清晰(worker保持无状态),在google的论文描述中,master和worker之间的通信是可以做的很简单的。只有两个语义的接口。
一个是worker节点向master请求一个任务,这时master根据整个mapreduce job的状态,可能有三种response:1. 分配一个map task任务; 2. 分配一个reduce task任务; 3. 不分配任务,告诉worker进入idle状态。master分配后会将当前的任务状态记录下来(idle -> in-progress)。
当worker完成任务后,将中间结果写在文件系统(在google的实现是分布式文件系统,GFS)中,然后记录文件路径,并将完成情况上报给master,由master记录这个task的状态和这个intermediate文件名。同时,当worker完成任务后,会进入idle状态,此时隔一段时间向master轮询任务。
总结下来,master需要提供这两个语义的接口给worker节点:
task get_task(worker)report_task(task, execute_result)
当然,在工业实现上,为了容错可能会做的更复杂,比如worker和master之间的心跳机制;或者允许集群重启恢复的check point机制。整体容错机制在下一节中详述。
fault tolerance
一个mapreduce任务可能需要成百上千个节点共同完成。所以整个集群必须有简单优雅的容错机制。
一个最常见的failure是worker节点挂掉或者和master节点的通信出现问题。mapreduce会引入master-worker之间的心跳机制,当master ping了之后收不到worker的回复,会认为worker已经挂掉,并将这个task状态更新为idle。
同时mapreduce是单主的集群,怎么对master节点的不可用做容错呢?一个做法是定期对master状态做check point,这个状态可以落盘到分布式文件系统中,下次启动时,读取check point继续任务。
代码解释
了解整个系统架构和机制后,尝试做一个简单的实现。MIT的6.824提供一个的lab,可以基于这个框架一个go语言的最简版实现。关于课程的描述,可以看这里:https://pdos.csail.mit.edu/6.824/labs/lab-mr.html,只需要一个go runtime就可以做了,下面是主要代码:
Master节点
master节点的状态结构:
type JobState int
const (
Start JobState = 0
MapPhase JobState = 1
MapFinished JobState = 2
ReducePhase JobState = 3
Finish JobState = 4
)
type Master struct {
// Your definitions here.
State JobState // current state of a mapreduce job.
Files []string // file names.
MapTaskStates map[int]TaskState // states of each map task 0=not start, 1=in progress, 2=finished.
ReduceTaskStates map[int]TaskState // states of each reduce task.
NReduce int
NMap int
}
然后是创建master节点的入口:
func MakeMaster(files []string, nReduce int) *Master {
m := Master{}
// master节点需要保存的状态:
// 文件名字
// 当前阶段
// map阶段:有哪几个文件已经被处理,哪几个文件未被处理
// map的intermediate文件的元信息
// 每个task的状态
m.Files = files
m.State = Start
// init map task state
m.MapTaskStates = make(map[int]TaskState)
m.ReduceTaskStates = make(map[int]TaskState, nReduce)
for i, _ := range m.Files {
m.MapTaskStates[i] = Idle
}
m.NReduce = nReduce
m.NMap = len(files)
m.server()
return &m
}
这是启动一个master的入口,是lab里面提供的模板代码,需要实现者填充代码。入参是两个:文件名路径数组,和指定reduce任务的数量。然后初始化master节点一系列初始状态,包括map任务和reduce状态的两个map,整个Job的状态。最后的m.server()由框架实现,打开tcp端口监听来自worker节点的rpc调用。
如前文所说,master节点需要提供两个api,一个是创建任务CreateTask,一个是提供给worker节点汇报任务完成情况ReportTask:
func (m *Master) CreateTask(args *NoArgs, reply *Task) error {
if m.State == Start || m.State == MapPhase {
mapID := -1
for i, taskState := range m.MapTaskStates {
if taskState == Idle {
mapID = i
m.MapTaskStates[i] = InProgress
}
}
reply.MapFileName = m.Files[mapID]
reply.Type = Map
// map id is simply the index of the file array
reply.MapID = mapID
reply.ReduceID = 0
reply.NReduce = m.NReduce
reply.NMap = m.NMap
// update state
m.State = MapPhase
} else if m.State == MapFinished || m.State == Finish {
reduceId := -1
for i, taskState := range m.ReduceTaskStates {
if taskState == Idle {
reduceId = i
m.ReduceTaskStates[i] = InProgress
}
}
reply.Type = Reduce
reply.MapID = 0
reply.ReduceID = reduceId
reply.NReduce = m.NReduce
reply.NMap = m.NMap
// update states
m.State = ReducePhase
} else if m.State == Finish {
reply.TaskType = Stop
}
return nil
}
这里下发task的策略是根据master当前状态判断应该下发map任务还是reduce任务。然后找到一个未执行(状态为Idle)的任务,下发给worker。(如果是map任务,还会把对应的fileName下发)。最后更新状态位。关于一个task的结构,下文中会提及。
然后是ReportTask,这个接口会在worker完成任务后调用:
func (m *Master) ReportTask(args *NoArgs, task *Task) error {
fmt.Printf("Master.Inspect is called.")
mapID := -1
// update task states
if task.Type == Map {
m.MapTaskStates[task.MapID] = task.TaskState
} else if task.Type == Reduce {
m.ReduceTaskStates[task.ReduceID] = task.TaskState
}
allFinish := true
// update job state if needed
if task.Type == Map && task.TaskState == Completed {
for id := 0; id < m.NMap; id++ {
if m.MapTaskStates[id] != Completed {
allFinish = false
break
}
}
if allFinish {
m.State = MapFinished
}
} else if task.Type == Reduce && task.TaskState == Completed {
for id := 0; id < m.NReduce; id++ {
if m.ReduceTaskStates[id] != Completed {
allFinish = false
break
}
}
if allFinish {
m.State = Finish
}
}
return nil
}
master的ReportTask接口主要就是更新task状态和job状态。代码也比较简单。
Worker节点
worker节点启动后,会定期轮询master节点获得一个task然后执行,先来看看Task结构的定义:
type TaskType int
type TaskState int
const (
Map TaskType = 0
Reduce TaskType = 1
)
const (
Idle TaskState = 0
InProgress TaskState = 1
Completed TaskState = 2
)
type Task struct {
Type TaskType
TaskState TaskState
NReduce int // reduce tasks count
NMap int // map tasks count
Mapf func(string, string) []KeyValue // map function
Reducef func(string, []string) string // reduce function
// map task require info
MapFileName string // the input filename that for a map task
MapID int // map task id
// reduce task require info
ReduceID int
}
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
task := GetTask()
if task.TaskType == Stop {
break
}
task.Mapf = mapf
task.Reducef = reducef
task.Execute()
ReportTask(task)
time.Sleep(30 * time.Millisecond)
}
}
因为worker已经去状态化,所以在整个worker生命周期里,可以执行多个task。其中,Mapf和Reducef是用户指定的map和reduce函数,由调用方实现,worker从master节点获取到task之后,会根据taskType(Map / Reduce)执行不同的func:
func (t *Task) Execute() bool {
if t.Type == Map {
t.doMap()
} else {
t.doReduce()
}
t.TaskState = Completed
return true
}
这里重点是map function和reduce function的执行:
func (t *Task) doMap() bool {
fmt.Printf("Task.map Execute, fileName: %s", t.MapFileName)
file, _ := os.Open(t.MapFileName)
content, _ := ioutil.ReadAll(file)
file.Close()
kvs := t.Mapf(t.MapFileName, string(content))
intermediate := make([][]KeyValue, t.NReduce, t.NReduce)
for _, kv := range kvs {
idx := ihash(kv.Key) % t.NReduce
intermediate[idx] = append(intermediate[idx], kv)
}
for idx := 0; idx < t.NReduce; idx++ {
intermediateFileName := fmt.Sprintf("mr-%d-%d", t.MapID, idx)
file, _ = os.Create(intermediateFileName)
data, _ := json.Marshal(intermediate[idx])
_, _ = file.Write(data)
file.Close()
}
return true
}
doMap就是读取相应的文件,调用MapF生成K-V对,然后根据哈希函数得到要将当前key分配到哪一块中,总共有NReduce块,最后根据这么块生成对应map以及reduce块的intermediateFile。比如一个MapID为0的map task,nReduce为3,最后生成3个文件:mr-0-0,mr-0-1,mr-0-2。
接下来是reduce,会从intermediateFile里读取出内容,然后将所有key-value对聚合起来,然后调用reduceF获得最后结果,写入到mr-out文件:
func (t *Task) doReduce() bool {
fmt.Printf("Task.doReduce execute")
kvsReduce := make(map[string][]string)
for idx := 0; idx < t.NMap; idx++ {
intermediateFileName := fmt.Sprintf("mr-%d-%d", idx, t.ReduceID)
file, _ := os.Open(intermediateFileName)
content, _ := ioutil.ReadAll(file)
file.Close()
kvs := make([]KeyValue, 0)
_ = json.Unmarshal(content, &kvs)
for _, kv := range kvs {
_, ok := kvsReduce[kv.Key]
if !ok {
kvsReduce[kv.Key] = make([]string, 0)
}
kvsReduce[kv.Key] = append(kvsReduce[kv.Key], kv.Value)
}
}
result := make([]string, 0)
for key, val := range kvsReduce {
result = append(result, fmt.Sprintf("%v %v\n", key, t.Reducef(key, val)))
}
outFileName := fmt.Sprintf("mr-out-%d", t.ReduceID)
ioutil.WriteFile(outFileName, []byte(strings.Join(result, "")), 0644)
return true
}
完成后,worker调用report接口通知master,master收到后记录状态,并同步更新整个job的状态:
// report a task after its execute
func ReportTask(task Task) bool {
args := NoArgs{}
call("Master.ReportTask", &args, &task)
return true
}
总结一下
在整个实现上,我处理得比较简单,一是没有考虑处理过程出错和worker节点不可用的容错逻辑,二是当前仅考虑map和reduce任务是在同一个节点上运行的(在实际情况中不可能发生),所以不需要考虑移动文件所需要的网络开销;同时没有考虑go语言的一些特性。
本文主要是想介绍mapReduce的架构设计的思想,并通过简单的实现,重温一下分布式系统设计所需要考虑的各种问题。
ref
- 《Designing Data-Intensive Applications》
- https://en.wikipedia.org/wiki/Batch_processing
- https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
- https://datawhatnow.com/batch-processing-mapreduce/#:~:text=Batch%20processing%20is%20an%20automated,the%20same%20or%20different%20database.
- https://www.cnblogs.com/fydeblog/p/12826673.html