
写可维护的业务系统(代码)
最近有机会一个人负责、主导一个项目。其中一项工作,就是需要从零开始写代码做一个code project。在整个过程中,我一直在学习和思考怎么写可维护的代码,写一个可以 一直维护,一直迭代,却把复杂度控制在一定的范围之内 的项目。
为什么我对这事感兴趣?因为看过太多悲剧的产生:在我参与的所有代码项目里(我参与工作以来一直写的是业务系统),几乎全部都会陷入这样的境地:对复杂度完全没有把控,对新增的需求,新增的领域知识,只能通过新增模型,新增接口,新增面条式的代码完成。直到复杂度增加到后人无法理解的地步 – 重写项目。
我们是可以做的更好的。下面说说我的想法和经验。
起码,分个层(建立多层次的抽象)
现在的项目一般会使用第三方框架,业务开发人员的代码相当于在一个框架里填入自己的业务逻辑。也就是说,这种项目天然的有来自框架的抽象,天然的有分层。
但是除此之外,业务开发人员的代码基本上是“事务脚本”,也就是将这件接口要做什么,从头到脚写出来,通常是这样:在数据库里拉出什么对象,改里面的某些值,然后在调用持久层的方法放回去。这样的问题是什么?是 缺乏抽象层次的代码不能表现领域逻辑。这样的代码如果人员调动频繁,而且缺乏文档和注释,这些代码的意图就会难以理解。
更麻烦的情况是,将技术细节(比如访问mq中间件,redis的访问细节)耦合在这种事务脚本里,导致代码更难维护。
正确的代码分层和好的OO设计可以很大程度的解决这个问题。它的思想也和其他领域的分层类似:每一层专注在解决自己的问题,下层对上层提供抽象。
很多ddd的书里喜欢把代码分层这样设计:
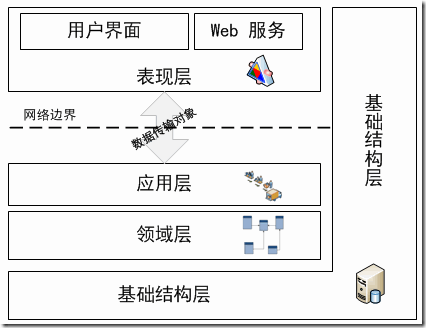
在学了一些DDD的方法和理念之后,在我最近的这个项目中,项目采用这样的架构:
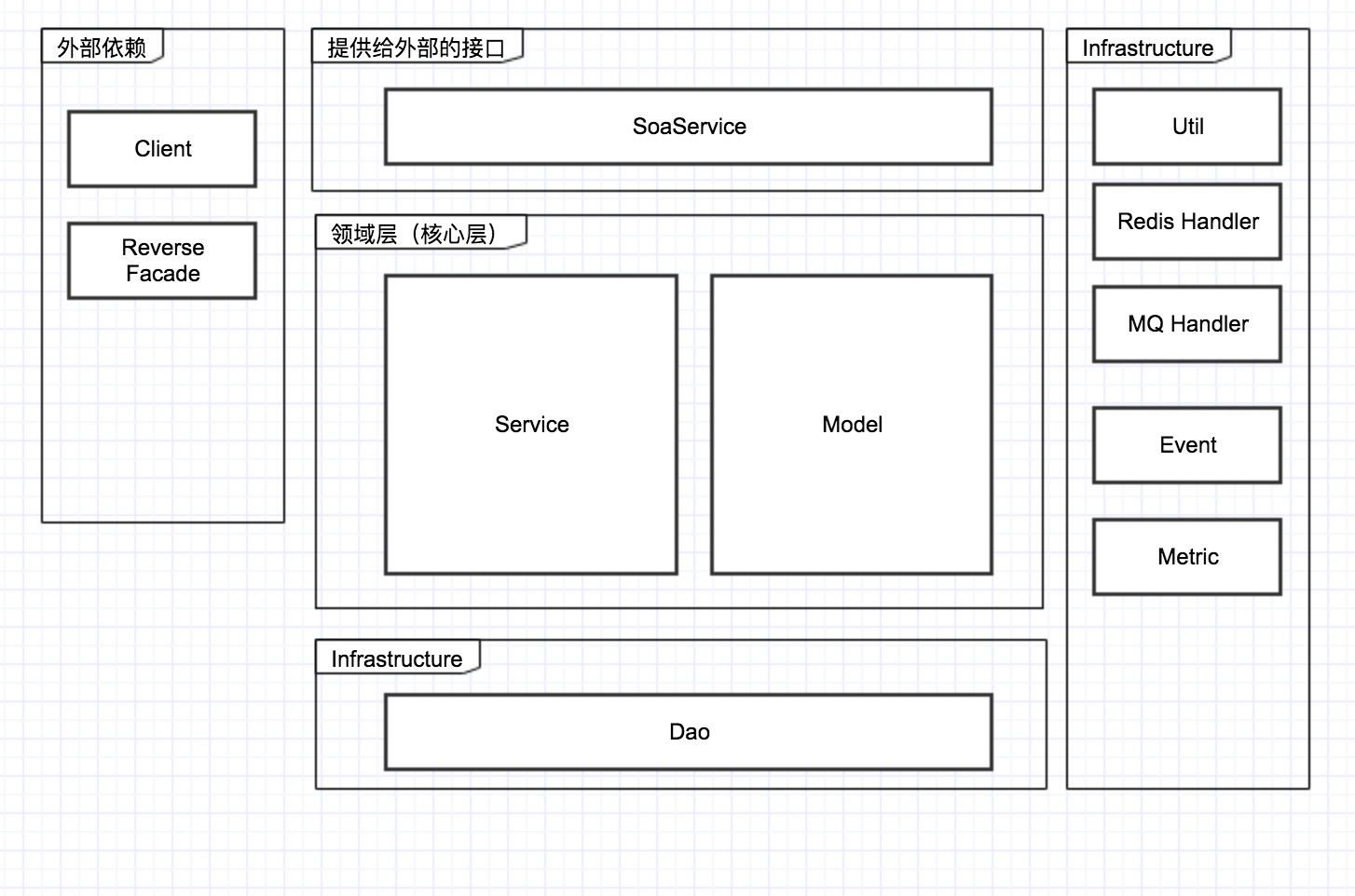
- 外部依赖层:封装对外部领域的依赖。包括:接口,外部DTO,transformer。(为什么要封装?该怎样封装?可以看 #怎样访问外部 一节)
- 提供给外部的接口层:提供给外部调用的层次。这层的角色像是项目里的协调者,一般会做这些事:
- 向下调用领域层的服务,完成对领域对象的操作。
- 调用redis,Mq组件的方法,完成除了业务逻辑之外支路逻辑。
- 发布领域事件
- 领域层:封装重要的领域逻辑。在理想的情况下,这一层可以完全用model来表示,但在实现上,除了model之外,还有很多的service对象。具体代码下详。
- 基础设施层:封装项目对其他基础设施的依赖,如:redis,mq,dao。另外一些util的类也会在这一层。
用模型模型表现领域逻辑
先来说说领域层。业务逻辑可以看成是领域模型的相互协作和影响。正确建模,然后在代码里把模型之间的关系显式的表达出来,是提高整个项目可维护性的第一步。
让模型有表达的能力
先看几个bad taste。以我最近写的项目,店铺配送举例:一个店铺有配送费A、配送费B字段,且店铺的配送状态有可能改变,如果配送状态为A,则给外部返回配送费A,如果配送状态为B,则给外部返回B。
我看过很多bad taste的代码,看起来会是这样:
class Delivery {
private int deliveryFeeA;
private int deliveryFeeB;
private DeliveryStatus status;
}
class DeliveryTransformer {
public static DeliveryDTO transform(Delivery input) {
DeliveryDTO output = new DeliveryDTO();
// ...
if (input.getStatus() == DeliveryStatus.StatusA) {
output.setDeliveryFee(input.getDeliveryFeeA());
} else if (input.getStatus() == DeliveryStatus.StatusB) {
output.setDeliveryFee(input.getDeliveryFeeB());
}
return output;
}
}
这段代码的问题是:取配送费A还是配送费B的逻辑,实际上是 非常重要的领域逻辑。而这代码却将这段逻辑放在一个猥琐的角落,甚至跑出了领域层,到了外部接口层的transformer上去了。产生的问题不仅仅是代码复用差,更重要的是领域逻辑被淹没了。
修改方法就是把这段逻辑放在model层,也就是领域层:
class Delivery {
private int deliveryFeeA;
private int deliveryFeeB;
private DeliveryStatus status;
public int getDeliveryFee() {
return status == DeliveryStatus.StatusA ? deliveryFeeA : deliveryFeeB;
}
}
class DeliveryTransformer {
public static DeliveryDTO transform(Delivery input) {
DeliveryDTO output = new DeliveryDTO();
// ...
output.setDeliveryFee(input.getDeliveryFee());
return output;
}
}
上面的例子非常简单,思路就是将属于领域层的逻辑收归到model,这样的小重构使代码变得可复用,可维护。当领域层能表达足够多的领域逻辑时,实现新的需求变成了:调整 / 修改领域模型,使它更能描述当前领域。(至于怎么挖掘和发现模型,怎样对领域建模,不在本文的讨论范围,可以移步《领域驱动设计》)。
接下来我们讨论,有什么逻辑应该移动到领域模型内:
- 状态类表述。模型得起码知道自己的类型 / 状态 / 属性。如上述例子。重构的方法也比较简单。
- 关键动作。领域模型能自己完成的关键动作。
-
tell。有时,别的模型,或service对象,需要借助当前模型的领域知识。这样的领域知识,也应该封装在model里。举个例子:
对审核流任务建模,一个重要的领域逻辑是:当这个任务在生命周期的什么阶段,谁可以对这个任务有怎样的操作?直接上代码:
class AuditJob { private AuditStatus status; } class AuditService { public void submitAction(Long jobId, User user, Action action, String remark) { AuditJob job = AuditJobRepository.find(jobId); if (job == null) { throw new NotFoundException(); } if (job.getStatus() == AuditStatus.Success || job.getStatus() == AuditStatus.Fail) { throw new ServiceException(); } if (job.getStatus() != AuditStatus.Initiailize && user.getRole() == UserRole.User) { throw new ServiceException(); } // ... } }上面代码中,AuditJob这个领域模型有足够的知识告诉上层,什么角色,什么操作,是允许的。这样的判断应该封装在model里:
class AuditJob { private AuditStatus status; public boolean actionIsValid(UserRole role, Action action) { if (this.isFinished()) { return false; } if (role == UserRole.User && status == AuditStatus.Initiailize) { return false; } // ... } public boolean isFinished() { return status == AuditStatus.Success || status == AuditStatus.Fail; } } class AuditService { public void submitAction(Long jobId, User user, Action action, String remark) { AuditJob job = AuditJobRepository.find(jobId); if (job == null) { throw new NotFoundException(); } if (!job.actionIsValid(user.getRole(), action)) { throw new ServiceException(); } // ... } }
借助Service Object填充领域层
在原教旨的ddd理论中,任何领域逻辑都应该表现在model层。但是在实际操作中,这样反而会让很多根本不会重用的逻辑放在了model层,发生了fat model的问题。
一个做法是在service做更多的事:
- 处理一些不会复用的业务逻辑。
- 协调多个model之间的协作,互动。
使用ddd构建聚合的概念
聚合(Aggregate)的概念是 一组高度相关的对象,作为一个数据修改的单元。无论是在建模上,还是在代码上,都是一个对控制复杂度,提高代码表达能力的非常有效的抽象。
关于聚合的概念可以参考《领域驱动设计》。
下面还是以我最近写的项目,店铺配送举例。
用代码表现聚合
当聚合被正确选择和设计出来之后,你就应该在代码层面表达这样的设计。
javax.persistence包有很多注解可以关联model(如:@OneToMany)。但我发现这种注解并不灵活,反而让持久化变得繁琐。我觉得更好的方法是自己动手创建聚合实体。
以店铺配送为例子,它可能有配送基本信息,配送规则,配送范围三个model,而聚合根是店铺id。那么聚合实体应该长这样:
public class Delivery {
private long shopId;
private DeliveryBase base;
private DeliveryRule rule;
private List<DeliveryArea> areas = new ArrayList<>();
}
当然,这样设计后,hibernate或其他的持久化框架是认不出这个聚合实体的。所以你需要自己组装这个聚合:
public class DeliveryRepositoy {
public Delivery get(long shopId) {
DeliveryBase base = DeliveryBaseRepository.findByShopId(shopId);
if (base == null) {
return null;
}
Delivery d = new Delivery();
d.setShopId(shopId);
d.setBase(base);
// ... find rule and areas
return d;
}
}
当有了这样的聚合对象后,尽可能在整个项目里都通过聚合访问和操作聚合内的模型(除持久化层外)。好处有两个:
- 提供一层抽象,封装聚合内部的细节。
- 控制项目外甚至项目中对整个聚合的访问。要保证这个聚合是修改更新的最小单元。
举个例子,有时一个接口可能只是修改这个配送聚合的DeliveryArea这个模型的某个值,这时仍然应该以整个配送聚合为单位进行:
SoaService层,提供以配送为粒度的接口:
public class DeliveryAreaSoaService {
public void createOrUpdate(long shopId, List<DeliveryAreaUpdateDTO> update) throws ServiceException;
}
在实现时,SoaService会调用领域层的service,完成对整个聚合的操作:
@Override
public void createOrUpdate(long shopId, List<DeliveryAreaUpdateDTO> update) throws ServiceException {
Delivery delivery = deliveryService.getBindMaster(shopId, productId);
if (delivery == null) {
throw new DeliveryNotFoundException();
}
Delivery updateDelivery = deliveryAreaService.set(delivery, transformer.transform(update));
validation.validateUpdate(delivery, updateDelivery);
deliveryService.save(delivery, updateDelivery);
}
deliveryAreaService是来自领域层的service,它对上层提供set方法的抽象:接受一个配送,接受更新信息,实现全部的业务逻辑,然后将整个聚合更新成正确的状态(即使改动的只是area模型),然后返回。
deliveryService提供save方法,是原子的持久化方法。
封装聚合内模型的互动
聚合本身可以有表达能力。原理和model的表达能力是一样的。除此之外更有价值的是,聚合封装了内部的互动,将涉及聚合内两个模型之间的领域逻辑表达出来。
比如,一个店铺配送的配送范围可能随着时间变化而改变,这种奇葩的业务逻辑非常需要正确的封装:
class Delivery {
private long shopId;
private DeliveryBase base;
private DeliveryRule rule;
private List<DeliveryArea> areas = new ArrayList<>();
public DeliveryArea getCurrentArea() {
LocalDateTime now = LocalDateTime.now();
if (base.isInRushHour(now)) {
return areas.stream().filter(DeliveryArea::isRushArea).findFirst().orElse(null);
} else {
return areas.stream().filter(DeliveryArea::isNormalArea).findFirst().orElse(null);
}
}
}
聚合内两个模型的动作,也应该封装在聚合model里。这个就不举例了。
在一致性边界之内建模真正的不变条件
标题这句话是说,聚合内的模型之所以会聚合起来,因为它们有真正的不变条件,不变的业务规则,任何操作都不能违背这些规则。这些条件应该在建模阶段就被发现。
而且,在聚合内这种不变条件的要求是非常严格的(如果不是,则可能是建模阶段有问题)。它必须要求 立即性,原子性 。其中,原子性可以用数据库事务实现,立即性则要求,每次修改聚合,都对整个聚合进行校验。
上面代码段有一行是:
validation.validateUpdate(delivery, updateDelivery);
实现是这样的:
public class DeliveryValidation {
private static Logger logger = Vine.getLogger(DeliveryValidation.class);
@Inject private CurrentDeliveryAreaValidator currentDeliveryAreaValidator;
@Inject private DeliveryAreaValidator deliveryAreaValidator;
@Inject private DeliveryRuleValidator deliveryRuleValidator;
@Inject private AreaGeometryValidator areaGeometryValidator;
private List<Validator> ALL;
private List<Validator> getAll() {
if (ALL != null) {
return ALL;
}
synchronized (DeliveryValidation.class) {
ALL = Arrays.asList(currentDeliveryAreaValidator, deliveryAreaValidator,
deliveryRuleValidator, areaGeometryValidator);
}
return ALL;
}
public void validate(Delivery delivery) throws DeliveryInvalidException {
for (Validator v : getAll()) {
v.validate(delivery);
}
}
public void validateUpdate(Delivery originDelivery, Delivery updateDelivery) throws DeliveryInvalidException {
try {
for (Validator v : getAll()) {
if (updateDelivery.isDeleted()) {
continue;
}
v.validateUpdate(originDelivery, updateDelivery);
}
} catch (DeliveryInvalidException e) {
DeliveryMetricCounter.logUpdatePathFail("validation", "validate-failed");
logger.error(String.format("shop_delivery validateUpdate failed. shopId: %s, productId: %s, error: ", updateDelivery.getShopId(), updateDelivery.getProductId()), e);
throw e;
}
}
}
public abstract class Validator {
public abstract void validate(Delivery shopDelivery) throws DeliveryInvalidException;
public abstract void validateUpdate(Delivery originDelivery, Delivery updateDelivery) throws DeliveryInvalidException;
}
在任何更新操作保存之前,都会调用validateUpdate方法,验证聚合是否满足不变的条件。
保存聚合
聚合的保存比想象中的复杂。聚合的保存需要原子性,一致性。这是通过数据库事务保证的。第二点是,每次更新都必须把整个聚合拉取出来,然后将整个聚合的所有模型保存一遍吗?
在上层来看,的确是这样的,但在下层,可以有更复杂的处理:
public void save(Delivery originDelivery, Delivery delivery) throws ServiceException {
Transactor t = null;
try {
t = deliveryDatabase.startTransaction();
doSave(originDelivery, delivery);
t.commit();
DeliveryMetricCounter.logUpdatePathSuccess("save-to-db");
} catch (Exception e) {
logger.error(String.format("id为%s的店铺 更新配送信息失败: %s", delivery.getShopId(), e.getMessage()), e);
DeliveryMetricCounter.logUpdatePathFail("save-to-db", "exception");
throw new OperationFailedException(e.getMessage());
} finally {
if (t != null) {
t.close();
}
}
}
private void doSave(Delivery originDelivery, Delivery delivery) {
if (delivery.getBase() != null) {
deliveryBaseDao.createOrUpdate(delivery.getBase());
}
if (delivery.getRule() != null && differ.needSave(originDelivery == null ? null : originDelivery.getRule(), delivery.getRule())) {
deliveryRuleDao.createOrUpdate(delivery.getRule());
}
if (!CollectionUtils.isEmpty(delivery.getAreas())) {
List<DeliveryArea> originAreas = originDelivery == null ? new ArrayList<>() : originDelivery.getAreas();
for (DeliveryArea a : delivery.getAreas()) {
DeliveryArea originArea = originAreas.stream().filter(oa -> Objects.equals(oa.getId(), a.getId())).findFirst().orElse(null);
if (differ.needSave(originArea, a)) {
deliveryAreaDao.createOrUpdate(a);
}
}
}
}
首先,持久化的时候需要传入两个对象:修改前的聚合和修改后的聚合。在持久化的时候,会通过differ.needSave方法比较原来的聚合和和更改后的聚合的内部模型,判断需要保存时,才调用dao的方法保存。
这样做会增加一些技术复杂度在持久层,但因为仅仅是技术复杂度,无伤大雅,不会增加项目理解的难度。
使用版本号 解决并发问题
使用版本号解决两个问题:
- 作为乐观锁,解决并发更新问题。
- 作为版本号,解决外部消息乱序问题。
实现起来非常简单:在聚合内部的其中一个模型加入version字段(通常是聚合根所在的模型),每次对整个聚合更新时,判断数据库中的version和内存中的version一致,且将version+1(hibernate有现成的注解@Version可以使用)。
用facade模式控制外部访问
在业务建模中,不同的限界上下文需要有信息交互。反映到项目代码就是:各种各样的接口调用。一个项目通常需要提供接口被人调用(输出),也会调用别人的接口(输入)。先来看看输出的部分,这部分的代码应该怎么优化?
简单的将所有外部接口分为两类:
- 读取接口 - GET。用DDD的语言来说,就是其他限界上下文需要用到当前领域的知识。
- 更新 - POST。用DDD的语言来说,就是其他限界上下文需要对当前领域产生影响。一般,一个领域需要对接多个其他的领域。反映到代码上,也就是需要提供各种更新接口给不同的调用方。
在设计外部接口的时候,我们希望:
- 限制外部访问。限制主要就两点:1. 限制字段的访问,2. 限流。
- 在完成了1的基础上,复用代码。
最好的手段是使用facade模式,在soaService层之上再增加一层facade接口。架构看起来会是这样:
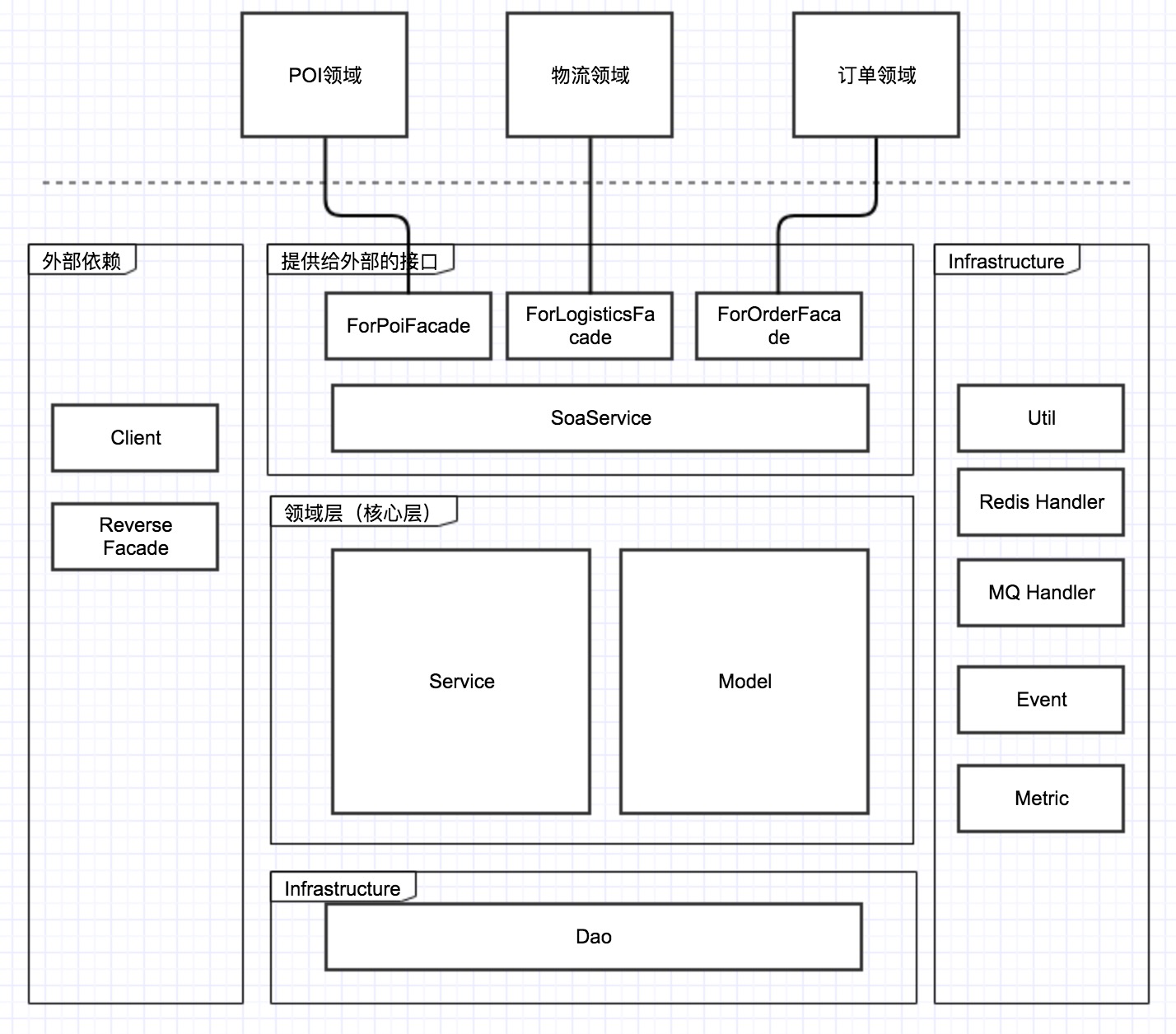
facade作为整个领域的最外层,由它提供外部接口,对接各方,facade层则向下调用soaService层。
代码示例:
facade接口:
public interface ForLogisticsFacade {
void changeDeliverStatusAndSetFee(long shopId, long userId, DeliverStatusDTO status, Integer fee) throws ServiceException;
}
店铺配送领域提供给物流领域一个接口:修改店铺配送的状态,同时修改配送费。
在facade接口实现时,会向下调用一个最通用的update接口:
public class ForLogisticsFacadeImpl implement ForLogisticsFacade {
void changeDeliverStatusAndSetFee(long shopId, long userId, DeliverStatusDTO status, Integer fee) throws ServiceException {
DeliveryUpdateDTO update = new DeliveryUpdateDTO();
update.setDeliveryStatus(status);
update.setDeliveryFee(fee);
deliverySoaService.update(shopId, userId, update, UpdateSource.LOGISTICS);
}
}
可见,facade接口相当于适配器,适配各个领域。它使外部接口免于暴露太多的领域细节,同时,通过正确调用soaService层的方法,实现代码复用。
那如果需要对接的方很多,会不会增加复杂度呢?只要保持facade只做简单的转发,不做具体业务逻辑。无论facade层怎么膨胀,都不会使人难以理解。因为真正有价值的领域知识都已封装在核心层。
怎样访问上下文外部
再来看看输入的部分,也就是调用其他项目的接口,有什么需要注意的?
通常调用其他项目的接口,拿到的是其他领域的实体。这种实体一般很难被当前领域理解。如果只是简单的消费某个接口的某个实体,可以直接调用。
但如果是当前接口对其他领域的某个实体有重度依赖,甚至两个领域之间有依赖,那么则需要将这个实体封装起来。
看一个bad case:
class Service {
@Inject private ElemeRestaurantService elemeRestaurantService;
public void execute() {
// ...
TRestaurant restaurant = elemeRestaurantService.get(message.getShopId());
Distribution currentDeliveryArea = DeliveryHelper.getCurrentDeliveryArea(restaurant);
ShopStatusDetail oldStatus = new ShopStatusDetail(
DeliveryHelper.getZeroDeliveryFees(restaurant),
AttrHelper.isLock(restaurant.getAttribute()),
currentDeliveryArea);
// ...
}
}
当时,这个项目有大量这样的代码,这个方法重度依赖店铺领域的TRestaurant实体。而这个实体都极其复杂,导致整个“事务脚本”在不停的解析这个实体,提取有用的信息,如:DeliveryHelper.getCurrentDeliveryArea,DeliveryHelper.getZeroDeliveryFees,AttrHelper.isLock的方法。
看上去没什么问题,因为解析的逻辑都抽离到各种“Helper”里了。但其实这仍然是面条式代码,只是将这些面条代码切割到不同的类里。不仅没有增加表达能力,而且比原来的代码增加了不必要的技术复杂度。(最终这个项目的结局是:因为技术复杂度太高而导致不能维护,需要重写)
比较好的方法是,既然在领域层一直需要用到TRestaurant实体,那么将它封装起来,让它看起来与其他的领域对象无异:
public class RestaurantForBalance {
private TRestaurant restaurant;
public long getShopId() {
return restaurant.getId();
}
public Distribution getCurrentDeliveryArea() {
// implementation...
}
public List<Double> getDeliveryFeeItems() {
// implementation...
}
public boolean isLocked() {
// implementation...
}
public static RestaurantForBalance build(TRestaurant tRestaurant) {
Objects.requireNonNull(tRestaurant);
RestaurantForBalance r = new RestaurantForBalance();
r.restaurant = tRestaurant;
return r;
}
}
同时,对调用方的接口也提供封装:
public class ErsClient {
@Inject
private ElemeRestaurantService elemeRestaurantService;
public RestaurantForBalance getRestaurantForBalance(Long restaurantId) {
TRestaurant tRestaurant = elemeRestaurantService.get(restaurantId);
if (tRestaurant == null) {
return null;
} else {
return RestaurantForBalance.build(tRestaurant);
}
}
}
最后,在service层将不再访问TRestaurant实体,而是访问RestaurantForBalance实体:
class Service {
@Inject private ErsClient ErsClient;
public void execute() {
// ...
RestaurantForBalance restaurant = ersClient.getRestaurantForBalance(message.getShopId());
Distribution currentDeliveryArea = DeliveryHelper.getCurrentDeliveryArea(restaurant);
ShopStatusDetail oldStatus = new ShopStatusDetail(
restaurant.getDeliveryFeeItems(),
restaurant.isLocked(),
restaurant.getCurrentDeliveryArea()
);
// ...
}
}
使用领域事件分离支路逻辑
还有一个设计模式的运用,能达到不写“事务脚本”的目标,值得一提。
在所有领域中,总是有相同的情况重复出现:领域中发生了某件事,需要对这件事做一些后续的操作,或者广播通知。例如,用户在完成注册后,系统会发出一封带有确认信息的邮件到用户的邮箱;用户关注的好友发送动态后他会收到相应的通知等等。
把这种经常出现的情况抽象为了领域事件。将(不含领域知识的)支路逻辑抽取到领域事件的handler中实现。第二个好处是,一般来说,支路逻辑是可以异步化的,这样分离之后更容易实现异步化。
领域事件使用发布订阅的设计模式实现的。这篇文章中,已经有代码表明怎样在infrastructure层构建这样的代码基础设施。
一般来说,聚合的更新一定是领域中重要的领域事件。我的建模是这样的:
public class DeliveryUpdatedEvent implements DomainEvent {
private Logger logger = Vine.getLogger(DeliveryUpdatedEvent.class);
private long shopId;
private Delivery origin;
private Delivery update;
private UpdateSource source;
private String remark;
private Long userId;
private long version;
private EventContext ctx;
private LocalDateTime occurredTime;
}
当这个领域事件发生之后,要做些什么,例如:发送mq信息,刷新redis缓存,记录changeRecord表。根据你的需求,编写不同的Subscriber并注册到Publisher即可。
参考
- 《企业应用架构模式》
- 《领域驱动设计》
- 《实现领域驱动设计》
- https://www.cnblogs.com/Leo_wl/p/4142064.html