
记一次线上CPU使用率飙升排查过程
前两天线上出了个CPU使用率飙升的问题。虽然最后是排查出来的,但排查时间太长了,思路还是有待提高。排查过程中用到非常多的JVM知识,一些是原来就会的,一些是边搞边学的(这就是慢的原因)。记录一下,下次遇到类似情况,整个时长应该可以缩短80%。
现象
相同的问题一共发生过两次。第一次发生在周二,当时看到的一个现象是CPU使用率飙升,另一个现象是rabbitmq的连接异常。当时第二个现象是一个很大的干扰项,我们怀疑的是rabbitmq中间件出问题了,后来中间件团队的人告诉我们,这个消息的q很久没有改动了,追查就断了。当时是用重启解决问题的。
第二次出现是周五,这时没有报任何异常,只是偶然的发现所有节点的CPU使用率都到了20%:
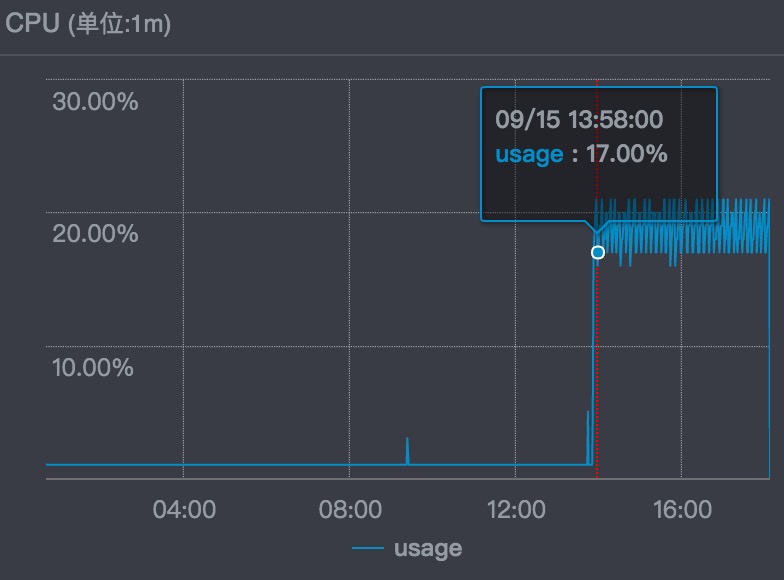
第二点是cms的GC时间突然上升:
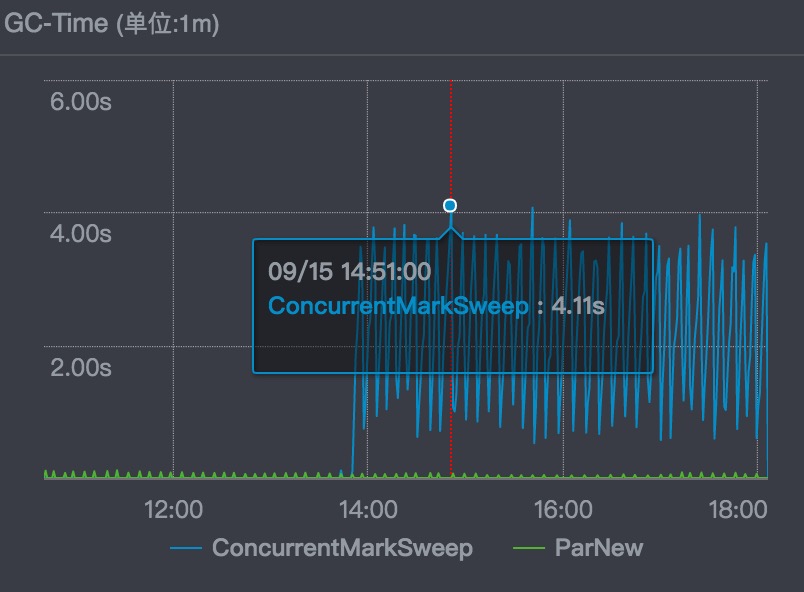
然后开始根据这个现象逐步追查下去。
找出在使用CPU的线程
遇到事故的第一个反应当然是:最近有没有发布?没有。最近一次发布是一个礼拜前了,而且那次改动绝不可能导致这个问题。
想到的第一件要做的事是:找出正在使用CPU的线程。SOP:
- top 或者 jps找到jvm实例的pid。
- top -Hp pid 找到线程的pid
- 将线程的pid转成16进制,用jstack就可以找到线程,然后可看到线程在跑什么代码。
这时因为我没有在生产环境跑jstack的权限,最后一步竟然扰攘了很久。最后找运维拉了jstack下来,定位到使用CPU的线程都是GC线程:

和第二个现象吻合:说明jvm正在进行大量的GC回收。
GC log
这时候登录到其中一个服务器看GC log,发现CMS的gc log不停地刷出来:说明jvm在不间断的执行full GC!
jstat没权限,于是这时又分析了一轮GC log,因为之前不熟悉这部分内容,所以很多信息都是边看边查。没查出个什么所以然。
推断出是内存泄漏
这时思路有点停滞了。回到监控页面再看集群的监控曲线,看看有没有别的线索。
这时看到堆内存的曲线不对:
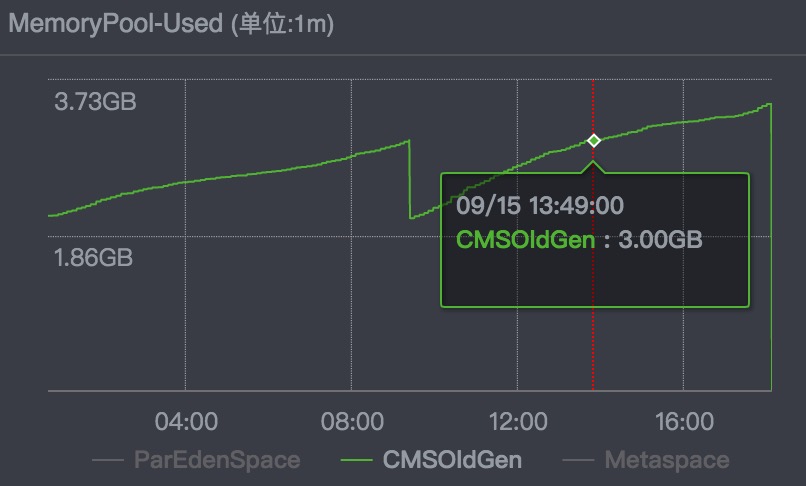
图中表示的时间点也就是事故发生的时间点:正常情况下,一次full GC应该会回收大量内存,所以 正常的堆内存曲线应该是呈锯齿形。但在这一次full之后,堆内存再也没有下降。
于是推断: 堆中有大量不能回收的对象且在不停膨胀,使堆的使用占比超过full GC的触发阈值,但又回收不掉,导致full GC一直执行。
推断出是内存泄漏问题了,于是jmap走一波吧。
用MAT分析内存泄漏原因
dump下来的内存快照是7g的对象…由于之前没处理过这么大的对快照,所以又耽误了一些时间。
最后,成功拉到MAT里,罪魁祸首一下就原形毕露了:
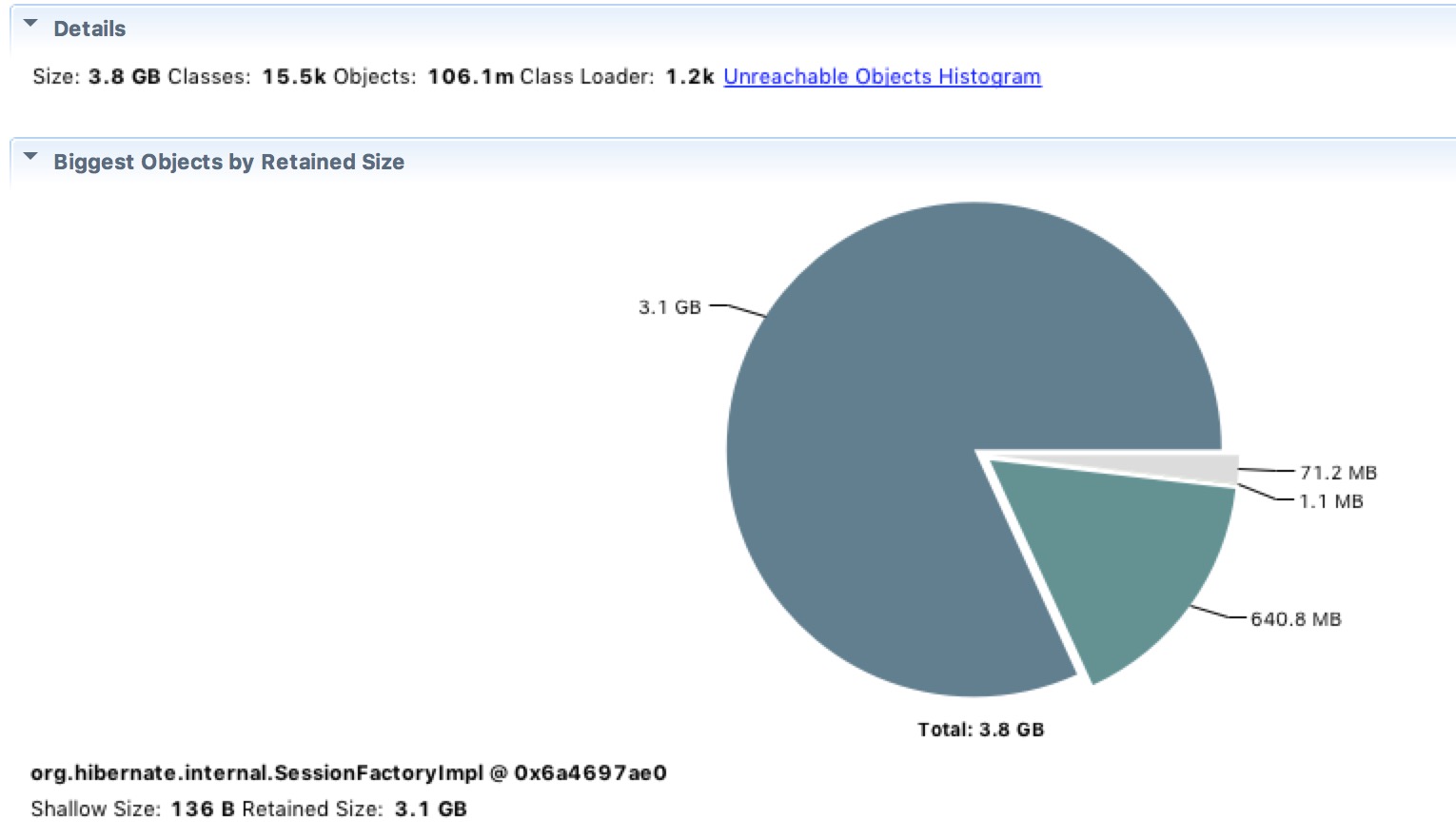
堆内存使用了3.8G,有一个3.1G的大对象占了82%的容量!
在查看这个对象究竟是什么:是hibernate的queryPlanCache:
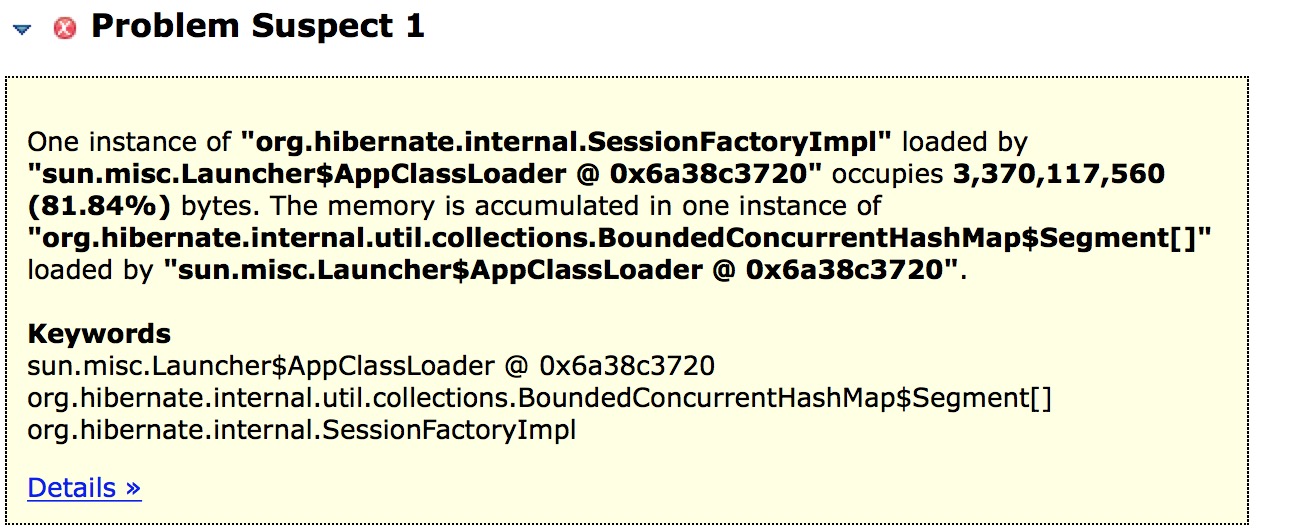
里面是一个巨型的hashmap:
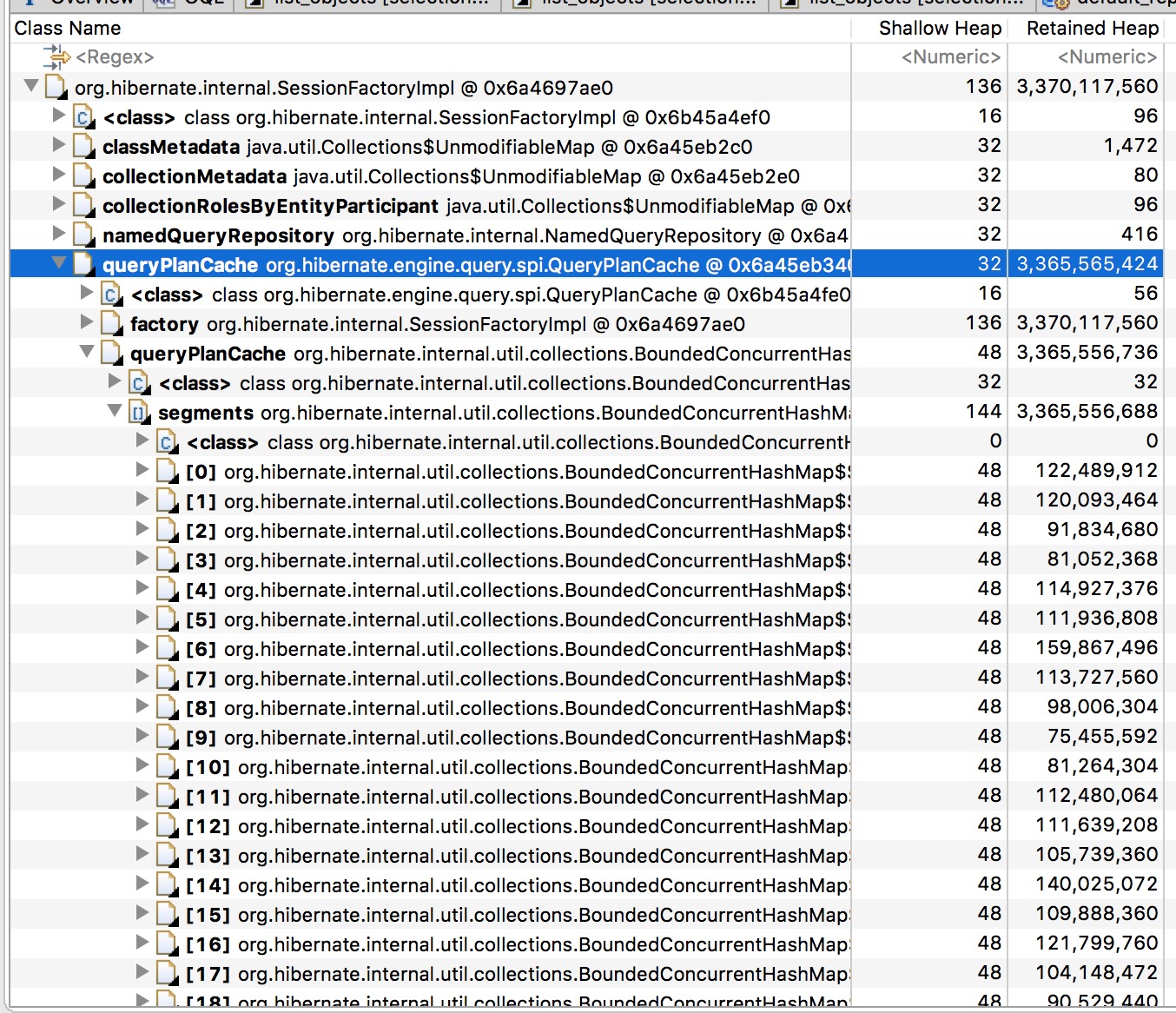
找到关键词了:queryPlanCache。google一下,很快定位到原因:http://stackoverflow.com/questions/31557076/spring-hibernate-query-plan-cache-memory-usage
定位root cause
这事还没完,queryPlanCache里缓存了什么?到底是哪些sql语句被缓存了导致泄漏的?
MAT里支持OCL这种查询语法,找到了这个对象大量缓存的是什么:
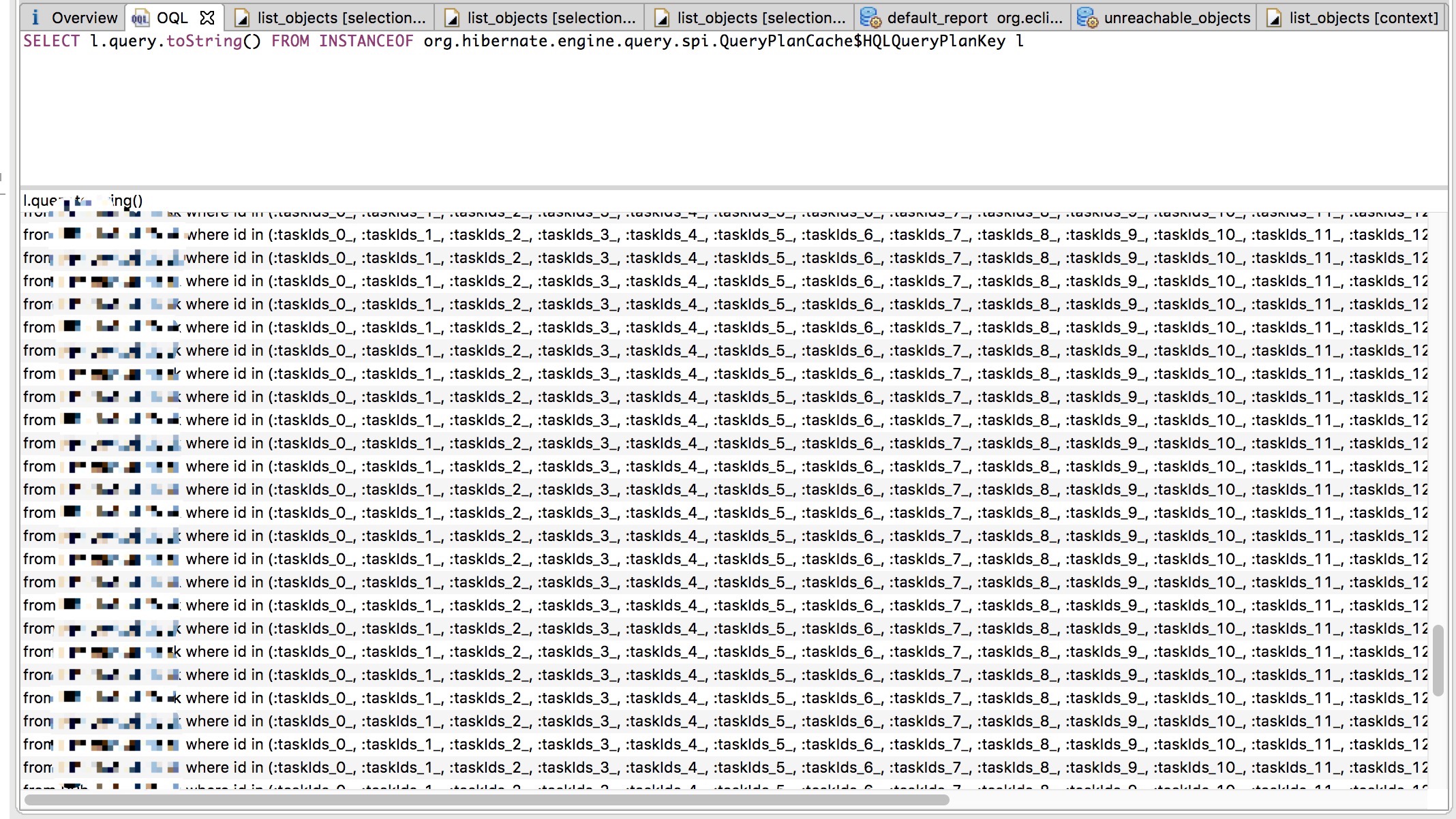
根据sql语句,搜索一下代码,很容找到root cause了。
问题是之前为什么没有这个问题呢?
因为最近都没有发布,之前为什么没有这个问题呢?看了一下代码,原来是某个代码的错误逻辑:sql语句的生成依赖es的搜索结果,前几天es和db不同步,导致生成了这种in 几千个id的sql语句。
这个系统的qps很低,所以出问题了不是性能出现瓶颈,而是这个诡异的问题。
这问题最快的定位方法是什么?
写起来思路很清晰,但实际上整个过程花费了大半天的时间,其实排查的过程中,有很多关键点没有抓到,有很多现象,是可以凭经验条件反射的推断出原因的:
- 看到cpu使用率上涨,用jstack看使用cpu的线程,以及该线程在跑什么代码。
- 找到是gc线程,然后看gc曲线是否正常。
- 看堆内存曲线,正常的曲线是锯齿形的,如果不是,一次full GC之后内存没有明显下降,那基本可以推断发生内存泄漏了。
- 怀疑是内存泄漏的问题,可以跑jmap,然后拉到MAT分析。
- 第四步比较耗时的话,可以同时跑这个命令:jmap -histo pid。看看有没有线索。
如果在思路清晰的情况下,这几步可以缩短到10分钟以内甚至更快。
总结
这一次掌握的排查问题的思路:
- 问题出现的时候有很多现象,要分清楚哪些现象是因,哪些现象是果,也就是说哪些导致问题出现,哪些现象是问题出现后带出来的。这点需要经验和冷静的推理。
- jvm的一些工具:jstack、jmap、jstat、jhat。包括可视化工具:MAT、jvisualvm,一定要掌握,并且要会看。
- 拿到进程状态,节点状态的SOP:找运维。
然后是在代码层面提高系统可用性的经验:
- 主流程应对外部依赖尽量少,比如es,能直接用db完成主流程的场景,不要依赖其他存储。
参考
- http://www.cnblogs.com/zhangxiaoguang/p/5792468.html
- http://stackoverflow.com/questions/31557076/spring-hibernate-query-plan-cache-memory-usage