
记一次线上问题排查过程
前几天出现了一个线上故障,将排查过程和验尸报告记录一下。
现象
开始的现象是收到报警短信:某个app id的异常飙升。赶回公司看监控面板:
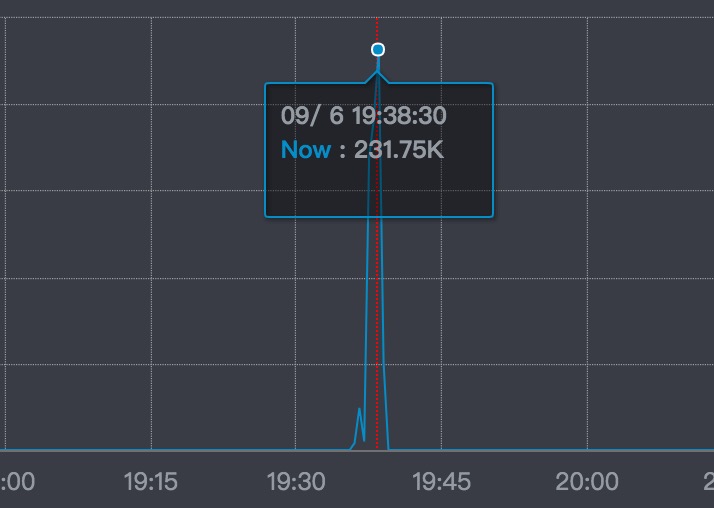
集群在报NoAvailableThreadException。怀疑是某个环节堵了。异常是从8个节点里报出来,集群中的其他节点没有出现无可用线程的异常。此是其一。
异常出现的时间很短,当看到监控面板的时候,异常已经回落。开始分析事故发生的时候现场到底发生了什么。
继续找线索
继续看trace上的其他信息:
出事期间,系统的QPS下降,响应时间上升:这时由于事故发生后大量的流量在等待服务器响应导致整个集群的吞吐量下降,应该是事故出现后导致的,不是成因。
QPS下降,也说明了当时系统没有被大流量冲击的情况出现。
再看报出NoAvailableThreadException的几个节点的JVM,CPU使用率,thread dump的情况:一切正常。
此时再看DATABASE曲线,发现问题了:事故期间insert语句的TPS突然升高。insert语句平均耗时到了3s。最高的耗时到了120s!而且是触发了mysql的超时。(这个120s在后来成为一个比较大的干扰信息)
通过trace上的堆栈信息找到当时疯狂发insert的接口。基本可以定位问题了。
进一步分析
这个接口是批量操作接口。接受一个ids数组,然后遍历数组,启动事务,向几个表查询,然后向几个表插入记录。
接口没有限制数组大小,也就是如果传一个1000个id的数组,会for循环1000次插入。
可以还原事故现场了:在当时这个接口被调用,传了一个很大的数组,导致DB堵了,所有到DB的连接都堵了,最终导致我们的服务集群无可用线程,报NoAvailableThreadException。
简单验证
确定一下确实是发生了这样的情况:第一个是捞ELK日志:事故前1分钟左右,这个接口的确被调用被传入大数组,而且相同的参数调用了8次。
第二,看thread dump:发现几乎所有线程都wait在C3P0的pool:
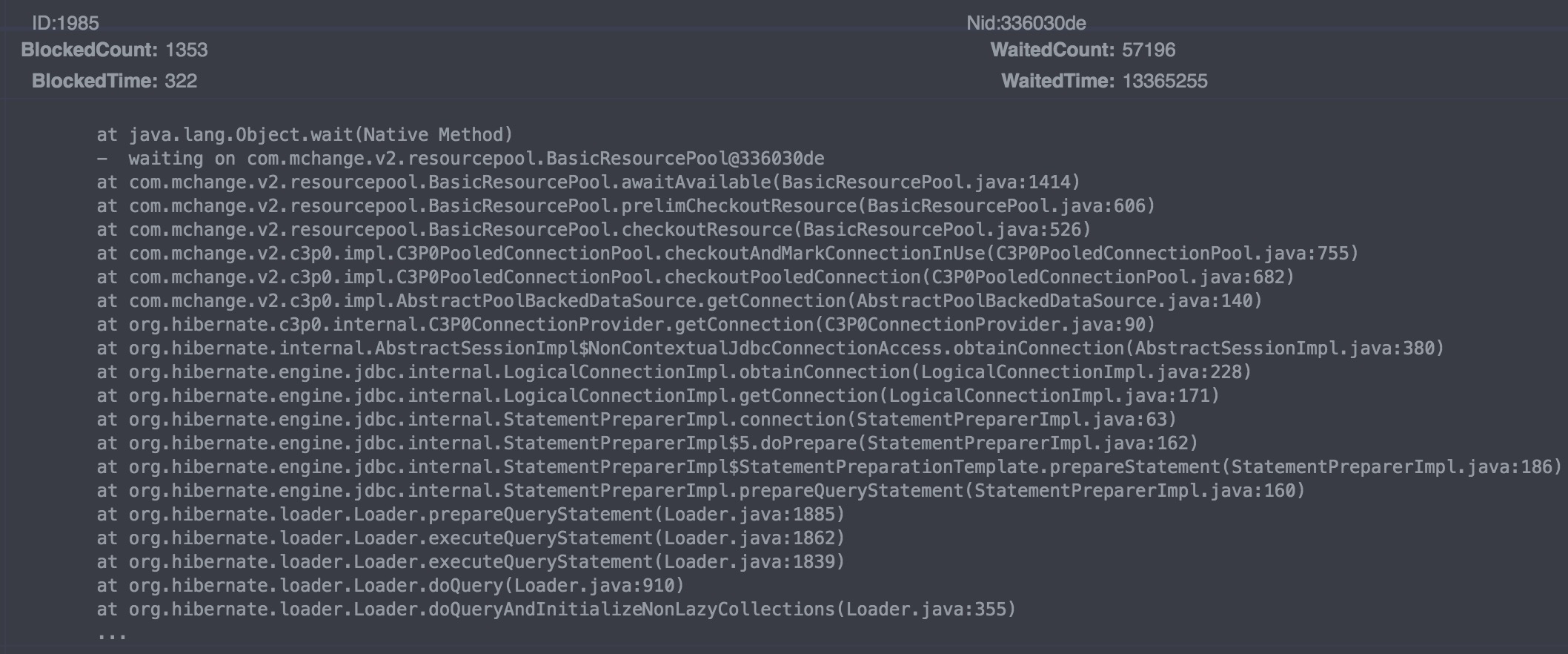
基本可以盖棺定论了吧?
可是不对啊
可是不对啊:第一:这时DBA和DAL(数据库中间件团队)告诉我们,DB和DAL根本没读,一直在等客户端发命令下来呢。
第二:insert语气的TPS虽然飙升了,但也就不到100的样子,怎么可能会堵住DB呢?
第三:如果DB堵了,那应该是整个集群都堵了,都会报NoAvailableThreadException,此时我再次查ELK日志确认:报这个异常的节点都被调用了这个接口的,也就是没被调用这个接口的节点,都没事。
而如果是堵在DB的话,那整个集群的所有节点都会堵了。
那就是说是在客户端的某个地方hang住了。而不是在DB层。此时干扰项又出现了:db出现的执行了120s的sql是怎么出现的?
google一下和请教老司机
就这样,想了很久都没有头绪,尝试在测试环境重现,也没法重现(由于线上的这个库是跨机房的,测试环境很难重现这样的网络延迟)。
这时请教DAL组的老大瞅一眼:
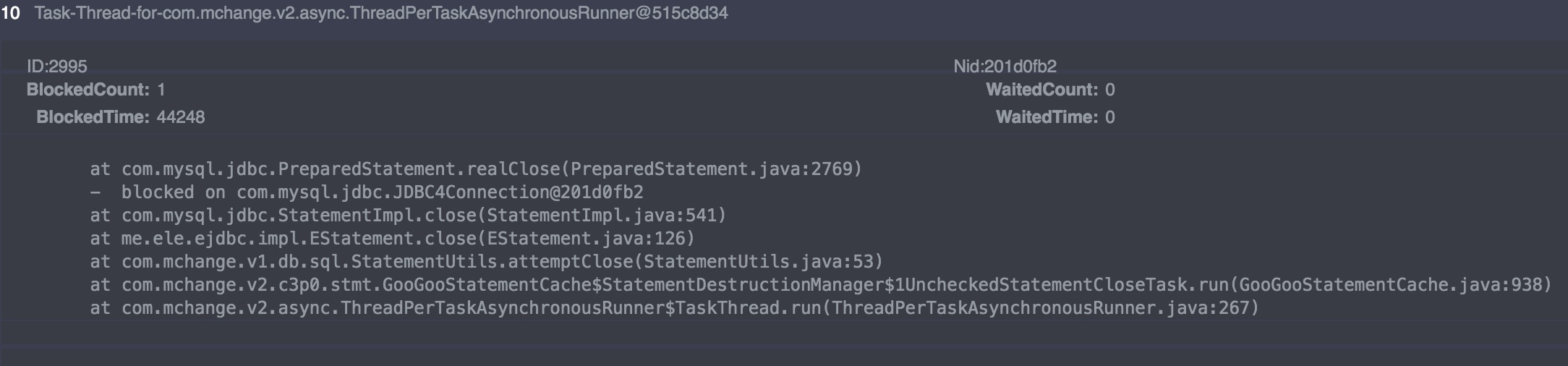
应该是触发了C3P0的一个preparedstatment已知bug:preparedstatment的死锁。
再google一下,应该就是这个问题:高并发的时候,触发C3P0的preparedstatment的cache pool死锁,资源不释放,如果线程请求这个cache pool,就会block住。
至于有sql执行很久的问题,再分析一下,是这样的:
这个接口的几个sql语句都在不同的事务中,sql语句发到db之后,db需要等一句commit,这句sql才算是真正执行。如果commit一直没下,就会触发数据库的120s超时。
另一点是应用每一次发送sql语句都需要访问下preparedstatment cache pool,然后再拿一个连接connection。此时如果堵了,那么这条语句就发不到db。
所以DB的120s超时是等一句commit等了120s都等不到,而不是这条sql语句跑了120s。
总结
至此,基本上所有现象都可以解释了。大概有10%的流量出现了3min的downtime。应该算是个小事故。
一个小事故能扯出这么多的基本知识和细节,搞高负载系统确实需要很多的知识。
DB / 数据库中间件这一层算是我的一个盲区,未来可以多看看这方面的知识。
参考
- http://www.theserverside.com/news/1365244/Why-Prepared-Statements-are-important-and-how-to-use-them-properly
- http://blog.csdn.net/t12x3456/article/details/7650404