
分布式系统 - 服务治理(一) - 限流
前文已经说过限流的概念和用法。理解起来或用起来都没什么高深的,最终目的都是限制并发,控制流量。本文主要讲一下它的几种实现和要解决的问题。
怎样实现?
限流的功能的可以这样实现:在大规模的分布式系统里,一定会有一个服务治理中心。它是一个service,也就是它有api,让用户(运维人员 / 工程师)实时修改配置,管理和治理整个分布式系统。这种api通常以web界面的方式暴露出来。在控制中心里手动输入这几个数值:服务名称、集群名称、限制的qps,然后改动就会实时生效。
常见方案
在具体实施的时候,有这几点细节需要考虑:
限流发生在哪?
限流应该发生在客户端还是服务端?
在客户端做限流的好处是:节省网络IO带宽、往返时间。
在服务端做限流的好处:简单。想想也知道在服务端做限流,代码好写。
通常限流的limit会设置为峰值的2倍以上。真出现有流量被限的话,也就总流量的不到10%(除非是非正常流量)。而且,限流通常是一个相对静态的设置,大部分情况下,限流起作用了说明我们的大部分请求都得到正确处理(否则,早就触发熔断了)。所以为了简单起见,选择服务器端限流吧。
分布式集群里,该怎样计数?
限流的粒度通常是集群级别的。比如限制一个集群的qps限流到1w qps,集群有10个节点部署。那么限流该怎样执行?
我原来以为一个集群会做一个redis的counter,让每个节点去incr这个counter,但发现这样做性能太差了:incr counter的操作是同步的。
正确的做法是:让每个节点知道自己的可以handle的qps,然后在节点内部各自实现counter的功能(可以在native内存中加计数器,在每个请求处理器先post process一下)。推送有几种方案:
- 让节点告诉配置中心自己的负载情况,在配置中心实时为每个节点分配权重。
- 给每个节点推送分配 1w / 10 = 1000 的qps限额。
显然第一个方案太难实现了。通常使用第二个方案,缺点很明显:平均主义。但workaround也很简单:让某个集群所有机器的配置都保持一致即可。
当集群的节点数改变时,限流大小是否需要动态变化?
当然需要,但这是另外一个话题:当一个节点被下线时,首先应该被服务治理中心知道。而限流大小的变化,是这个事件的其中一个回调。
被挡掉的流量作何处理?
既然限流发生在服务器端,是否可以让用户自定义一个fallback方法?否则抛出一个RateLimitException。调用方接收到这个异常又该如何处理?
限流算法
接下来讨论限流算法。讨论算法的时候,假设应用场景都为应用级别的限流。
计数器
第一个能想到的就是计数器算法。两句话说完这个算法就是:
- 用一个线程安全的counter作为计数器,每个请求来了,判断一下counter的数字是否溢出。如果没溢出,就通过请求,然后给counter+1,如果溢出,就拒绝该请求。
- 一定时间间隔counter归0。
问题也显而易见:这样对流量的限制是段式(存在时间粒度)的,而不是均匀的。
假设我限制qps为10000,如果第0.1s来了9000个请求,然后后0.9s来了1000个请求,那这一秒内这10000个请求都被允许。但实际上第0.1s的qps达到了(9000 / 0.1 = 90000)!
在一些极端情况下,这种误差有可能导致系统被冲垮。
漏桶算法
算法的思想很简单,看图:
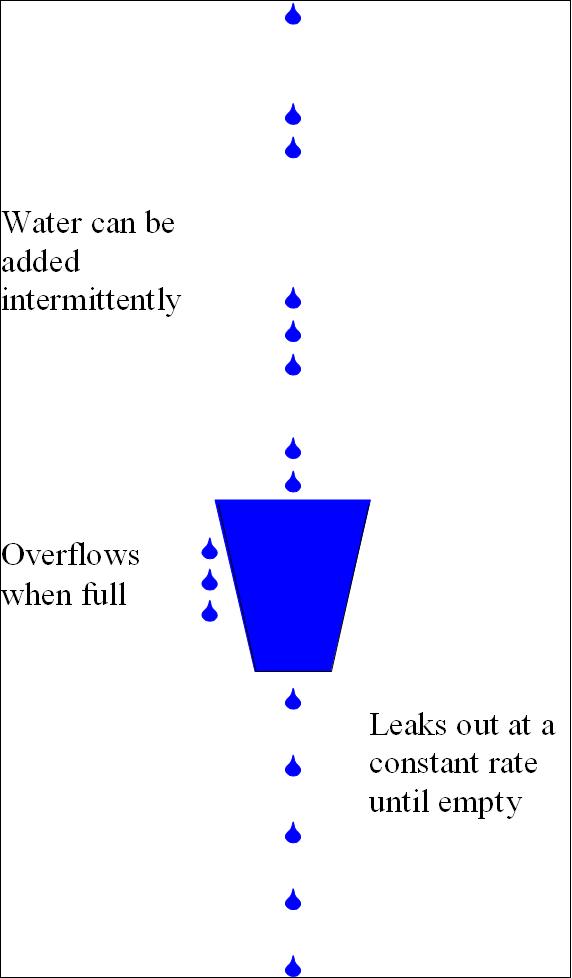
首先,我们有一个固定容量的桶,有水流进来,也有水流出去。流进的速度是无法控制的,我们做的是:保证水桶的水流出的速度总是固定的。
这样当流入的速度过大时,多余的水将会溢出。
参考
- http://www.kissyu.org/2016/08/13/%E9%99%90%E6%B5%81%E7%AE%97%E6%B3%95%E6%80%BB%E7%BB%93/
- https://en.wikipedia.org/wiki/Leaky_bucket