
从JMM层面说说Java并发(三) - ConcurrentHashmap(JDK1.6)
ConcurrentHashMap是JDK提供的一个线程安全的Map实现。在JDK1.6中,它使用锁分离和Segment的方法实现更小粒度的锁。而在JDK1.8版本中,ConcurrentHashMap基本放弃了这一做法,而是使用CAS算法实现。本文分析的是JDK1.6版本中的实现。
HashTable的问题
除ConcurrentHashMap之外,HashTable也是一个线程安全的Map实现。但是在多线程环境,不会使用HashTable,原因是:它的性能太低下。HashTable容器使用synchronized来保证线程安全,也就是一个HashTable对象是共享一个锁的:如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁。所以,一个优化思路是:调整内部数据结构,从而允许容器里有多个锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率。这就是ConcurrentHashmap使用的锁分段技术。
数据结构的调整
先复习一下HashTable的数据结构,是一个典型的哈希表实现:
- 使用数组存储Entry
- 使用拉链法解决哈希冲突
一个HashMap的数据结构看起来类似下图:
.gif)
也是因为这样的数据结构,HashTable只能有一个锁。
ConcurrentHashmap使用一个种粒度更细的加锁机制来实现高性能,看看ConcurrentHashmap的解决方法:
首先是它的内部类图:
.jpg)
类图的结构,实际也是运行时的内存结构,ConcurrentHashMap、Segment、HashEntry三者是嵌套关系:
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,
一个初始化好之后的ConcurrentHashMap,它的数据结构会如下图所示:
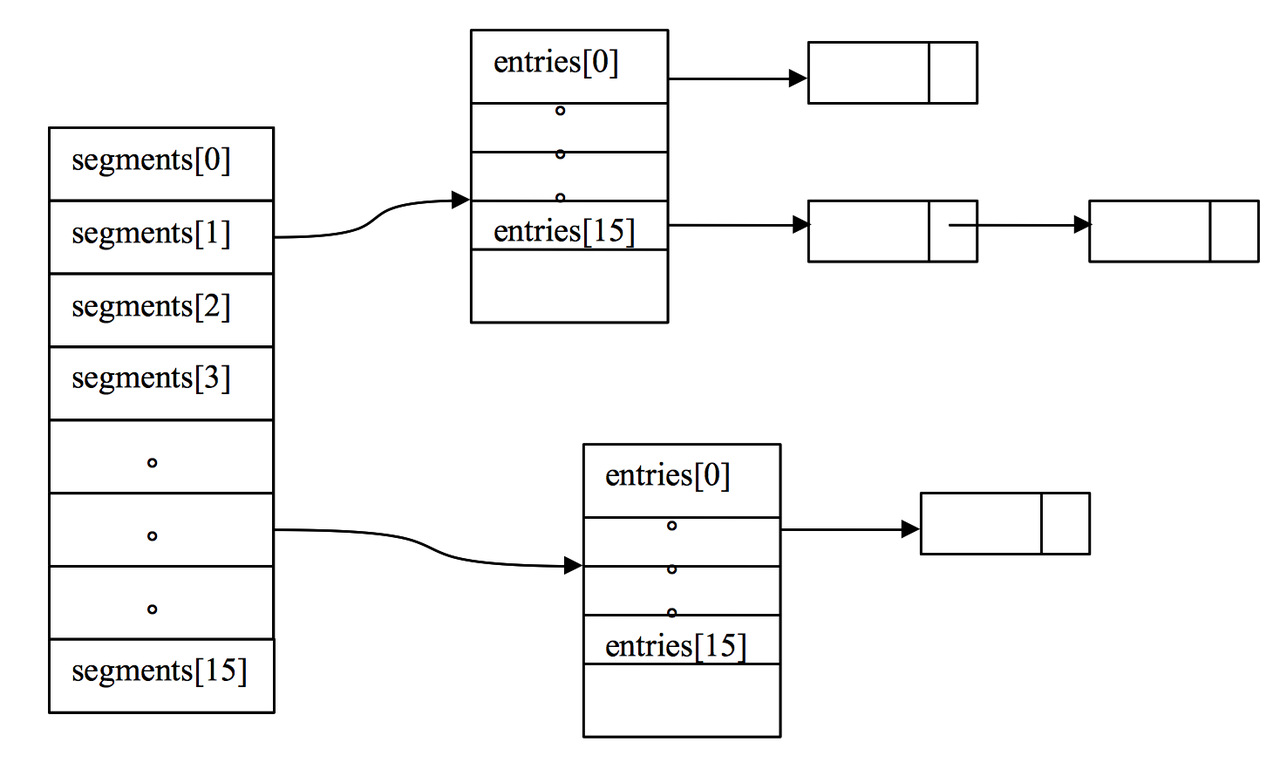
也就是一个ConcurrentHashMap实例下,会有一个segments数组,里面的每个segment持有HashEntry数组。
分离锁的操作方法
ConcurrentHashMap的做法相当于在对象和数据结构(存放每个K-V对的table)的中间,插入中间层(segments),把table数组分拆到不同的segment里。首先从数据结构上拆分table数组,降低粒度。
然后看看每个segment是怎么定义的:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
...
}
Segment继承了ReentrantLock,表明每个segment都可以当做一个锁,对每个segment中的数据需要同步操作的话都是使用每个segment容器对象自身的锁来实现。这样,每个Segment守护一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
这样的做法叫“分离锁(lock striping)”。也就是这样,已经大大提高了并发性能。
无须锁的get方法
首先看下get操作。同样ConcurrentHashMap的get操作是直接委托给Segment的get方法,直接看Segment的get方法:
V get(Object key, int hash) {
if (count != 0) { // read-volatile (1)
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null) //(2)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
在分析之前,我们想想看一个哈希表里的get操作,有可能有什么并发问题呢?我认为有这几个:
- 在get前,另一个线程 已经 put或者remove了这个segment中的一个entry,但由于没有足够的同步,当前线程没有看到。(如果不清楚为什么会有这种可能,请看之前的文章)
- 找到key的index之后,会沿着链表往下找到该entry(代码执行在1, 2之间的时候)。这个过程中,另一个线程恰好新增/删除了entry,或者改变了entry的value,但由于没有同步,当前线程没有看到。
对于第一点,是比较容易解决的,请看第一行,会先判断一下count != 0。正如你想的一样,count是一个volatile变量:
transient volatile int count;
每次put或remove方法都会修改count的值,也就是一个volatile写,而根据happens-before规则:对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作。这样,每次判断count变量的时候,即使恰好其他线程改变了segment也会体现出来。
对于第二点,简单来说,就是在遍历链表的过程中,segments的状态发生变化。是比较复杂的。我们分三种情况分析:
1. 该entry的value被另一线程修改了
这种情况比较好解决,HashEntry类结构:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
...
}
value也是volatile变量,利用volatile的同步能保证其他线程value的改变在get方法中是可见的。
2. 另一个线程新增了这个entry
首先,有一点要明确:ConcurrentHashMap使用拉链法解决哈希冲突,而同一个bucket里,新增的HashEntry是添加到 链表头 的:
.jpg)
也就是,出现并发问题的条件应是这样的:
- get方法刚通过hash值定位了entry的位置,准备遍历冲突链表。
- 而另一个线程调用put方法,插入的正是我们准备get的这个entry。
- 对于get线程来说,它刚好看到put线程正在执行
new HashEntry(K k , V v, HashEntry next),也就是entry未被完全初始化。(为什么说看到?因为根据JMM模型,get线程和put线程在这个场景中是没有足够的同步的,它只能根据主内存里的变量情况来“假想”put线程执行哪一步)
这种情况应当很罕见,这其实是出现了和DCL一样的结果:如果这是不加同步的就返回value,那么有可能返回一个状态未完全处理好的对象。
完全的理解了这个并发问题出现的原因,就能看懂这里的实现了:首先,明明put方法里是不允许放入value为Null的键值对的,为什么要判断:v != null呢?
这里出现v为空的情况只可能有一种:put线程执行new HashEntry(K k , V v, HashEntry next)的结果对于get线程尚未完全可见。这时,调用readValueUnderLock,则采用加锁的方式再次get。这时,读锁使用的是写锁,所以结果是可见的。
3. 另一个线程删除了这个entry
首先,因为结点类HashEntry的next指针是final的,所以删除方法的实现是:而是将要删除的节点之前的节点复制一份,形成新的链表。
假设我们的链表元素是:e1-> e2 -> e3 -> e4 我们要删除 e3这个entry,get线程顺着链表刚找到e1,这时另一个线程就执行了删除e3的操作。这种情况下程序会如何表现呢?
ConcurrentHashMap是没有足够的同步保证在这种情况下的正确性的。也就是说,这时e3即是被删除了还是会返回。但是这种情况不会有什么安全问题:即我们返回e3的时候,它被其他线程删除了,暴漏出去的e3也不会对我们新的链表造成影响。
跨segments的操作
pending…
参考
- http://ifeve.com/java-concurrent-hashmap-2/
- http://ifeve.com/concurrenthashmap/
- http://www.iteye.com/topic/344876
- http://www.ibm.com/developerworks/java/library/j-jtp08223/