
Ruby并发与线程
在计算机的世界里,并发的概念是:把多个任务同时进行,以节省时间/空间资源。并发是操作系统级别的概念,本文会在更高的层次讨论,所以会省略一些底层实现细节,如果你对多进程模型,多线程等相关概念不了解,先去看看Linux进程模型吧。:)
下面,从一个简单的例子讲起:
基本情况(串行)
并发的一个应用场景是计算密集的任务。举个例子:比如我们要分别分析100个用户的资料,分析过程可能非常复杂,每次分析需要超过100ms(简单起见,我用fib方法模拟),代码如下:
require "benchmark"
def fib(n)
n < 2 ? n : fib(n - 1) + fib(n - 2)
end
def heavy_task
fib(30)
end
puts Benchmark.measure{
100.times do |i|
heavy_task
end
}
运行一下,耗时:
12.650000 0.050000 12.700000 ( 12.830092)
用时12秒!在此场景中,显然每一个用户的资料分析是独立的任务,也就是说,不需要等A用户的分析完成了才分析B用户,每个任务都可以同时进行。那么,用并发优化它。
Fork
在实现层面,并发可以通过2种方式进行:
- 通过fork子进程
- 通过新线程
下文会详细比较它们两者,我们首先尝试用多进程实现的并发优化这段代码。
Ruby提供fork接口,它实际上是通过 调用POSIX标准的系统调用产生子进程的 。新产生的子进程与父进程不共享内存,它有新的堆栈;子进程由系统调度,所以,它与父进程是并发执行的。
通过Fork优化代码,并发耗时严重的任务:
require "benchmark"
def fib(n)
n < 2 ? n : fib(n - 1) + fib(n - 2)
end
def heavy_task
fib(30)
end
puts Benchmark.measure{
100.times do |i|
fork do
heavy_task
end
end
Process.waitall
}
优化后的结果:
0.000000 0.030000 18.660000 ( 2.379606)
2.3秒!使用fork,这段代码快了将近5倍。
但是等等,通过fork实现的并发会引入新的问题:每次fork都会把父进程的堆栈空间 完整地 复制一次到子进程内存中,也就是说,如果你的应用需要20mb的内存,这段简单的fork会消费 20mb * 100 = 2GB 的内存空间!而fork的目的不过是并发执行一个耗时的方法。
除了需要更多的内存空间之外,多进程的另一个缺点是:子进程之间必须以IPC通信(如管道),设想你需要把这些处理结果都放在一个数组里返回,用多进程优化并发处理后,数据就难以汇集了。
显然,在这个场景里,多线程并发是更好的选择。
Thread
那么,试试用多线程处理这段代码吧:
require "benchmark"
def fib(n)
n < 2 ? n : fib(n - 1) + fib(n - 2)
end
def heavy_task
fib(30)
end
threads = []
puts Benchmark.measure{
100.times do |i|
threads << Thread.new do
heavy_task
end
end
threads.map(&:join)
}
执行结果:
11.660000 0.080000 11.740000 ( 11.806760)
怎么回事?使用多线程只比串行版本快不到10%。
答案是Global Interpreter Lock(GIL)。因为有GIL的存在,Ruby的VM并不真正支持多线程。如果你完全不了解GIL:
MRI里有个东西叫全局解释器锁(global interpreter lock)。这个锁环绕着Ruby代码的执行。即是说在一个多线程的上下文中,在任何时候只有一个线程可以执行Ruby代码。 因此,假如一台8核机器上跑着8个线程,在特定的时间点上也只有一个线程和一个核心在忙碌。GIL一直保护着Ruby内核,以免竞争条件造成数据混乱。把警告和优化放一边,这就是它的主旨了。
也就是说,Ruby中的线程并不是并行的。
在此例中,heavy_task是一个CPU密集型的任务,所以在MRI中,多线程几乎不能带来任何优化。
但对于一些IO密集型的场景,如http请求,GIL对线程的影响就没那么大,多线程并发仍然可以提供不错的优化的。
当然,也有不使用GIL的Ruby解释器,如JRuby:
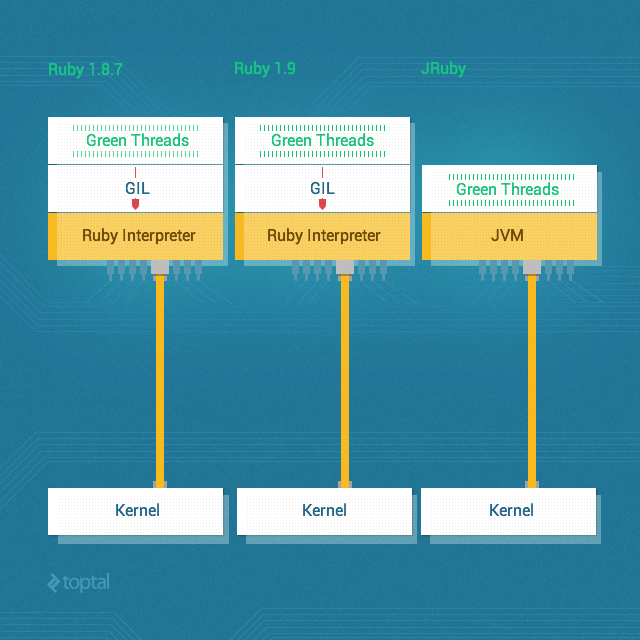
你可以在JRuby试试运行这段代码。
比较多线程和多进程
是时候比较一下多进程和多线程之间的区别了。
| 多进程 | 多线程 |
|---|---|
| 使用更多内存 | 使用更少内存 |
| 当父进程比子进程先退出时,子进程会变成僵尸进程 | 当进程退出时,所有线程都会退出 |
| 操作系统切换进程上下文时耗时更多 | 切换线程上下文时的消耗远小于进程 |
| 父子进程间的内存是独立的,意味着创建子进程时需要新的内存空间 | 线程间共享相同的内存,所以需要处理竞态条件的问题 |
| 进程的通信需要通过IPC(inter-process communication) | 线程间可以通过队列和共享内存通信 |
| 创建和销毁更费时 | 创建和销毁更快速 |
| debug更容易 | debug可能会非常坑 |
参考资源
- Ruby Concurrency and Parallelism: A Practical Tutorial (https://www.toptal.com/ruby/ruby-concurrency-and-parallelism-a-practical-primer)