
电商业务架构背后的Know-Why:关于一致性的思考和Best Practise
各种一致性模型和选型决策树
整个分布式系统的挑战和理论都集中在共识、容错、故障转移和一致性。关于分布式系统的共识和一致性,如果是研究和使用分布式数据库,例如Azure Cosmos DB,需要考虑的模型会很复杂:
- 强一致性 (Linearizability): 所有节点在任意时刻看到的数据是相同的,即系统保证对于任意两个操作,它们的执行顺序是一致的。
- 弱一致性 (Weak Consistency): 节点之间的数据同步不是实时的,可能存在一段时间的不一致,但最终会达到一致状态。
- 因果一致性 (Causal Consistency): 保持具有因果关系的操作的一致性,但对于无关的操作可以并发执行。
- 会话一致性 (Session Consistency): 在单个客户端的操作序列中保持一致性,不考虑其他客户端的操作。
- 最终一致性 (Eventual Consistency): 系统保证最终所有节点的数据是一致的,但在同步过程中可能存在一段时间的不一致。
但在一般的业务系统中,我们的选型和和决策过程会简单不少,因为这几个原因,可以让我们对一致性有很多的简化:
- 业务架构中,几乎用不到强一致性。想象下单的场景,比如两个用户,分别购买两个不同的商品。这两个事务之间,我们会关注它们的先后顺序吗?不会。就像海上的两朵浪花,在数据层面是无关联的。而只有少量的事务会产生关联,比如购买同一个商品,而这些问题,在日常可能占所有流量的<1%,都是有解法的。
- 对于非关键的场景,能容忍一定的不一致。回到下单-支付的场景,你可能遇到过明明支付成功,但结果页却显示未支付,需要刷新几次页面才显示出来;或者发布文章,自己在 timeline 上却刷新不到。这些场景都是:只要不发生不可逆的损失,我们对不一致都有一定程度的容忍。
在一般的业务场景的选型中,我们倾向于这样的 trade-offs:牺牲一部分一致性,来换取性能和可用性((BASE)[https://en.wikipedia.org/wiki/Eventual_consistency])。主要的决策关注点是这几点:
- 原子性 & 操作关联:当事务中的多个操作需要原子性时,即事务执行过程的中间状态,不能被观察;同时,每个操作之间,需要知道其他操作是否成功,或者失败。这时候,一般只能使用强一致性。
关于第一点,这里可以举两个例子:
- 下单。下单是个典型的需要原子性场景。多个域的资源扣减需要一起成功,一起失败。例如当库存扣减失败时,订单创建失败,此订单扣减的优惠券需要回滚。这样的场景,选择用分布式事务。
- 逆向订单履约阶段。这里举一个售后域的一个典型场景:支付域收到第三方的退款成功通知 -> 通知售后域更新逆向订单状态 -> 通知订单更新订单的逆向状态。这样的状态同步有几个特点: 1) 同步是单向的,上游保证自己成功;不需要关心下游失败而回滚。 2) 容忍短暂的不一致。 这样的场景下,使用最终一致是更优的解法。
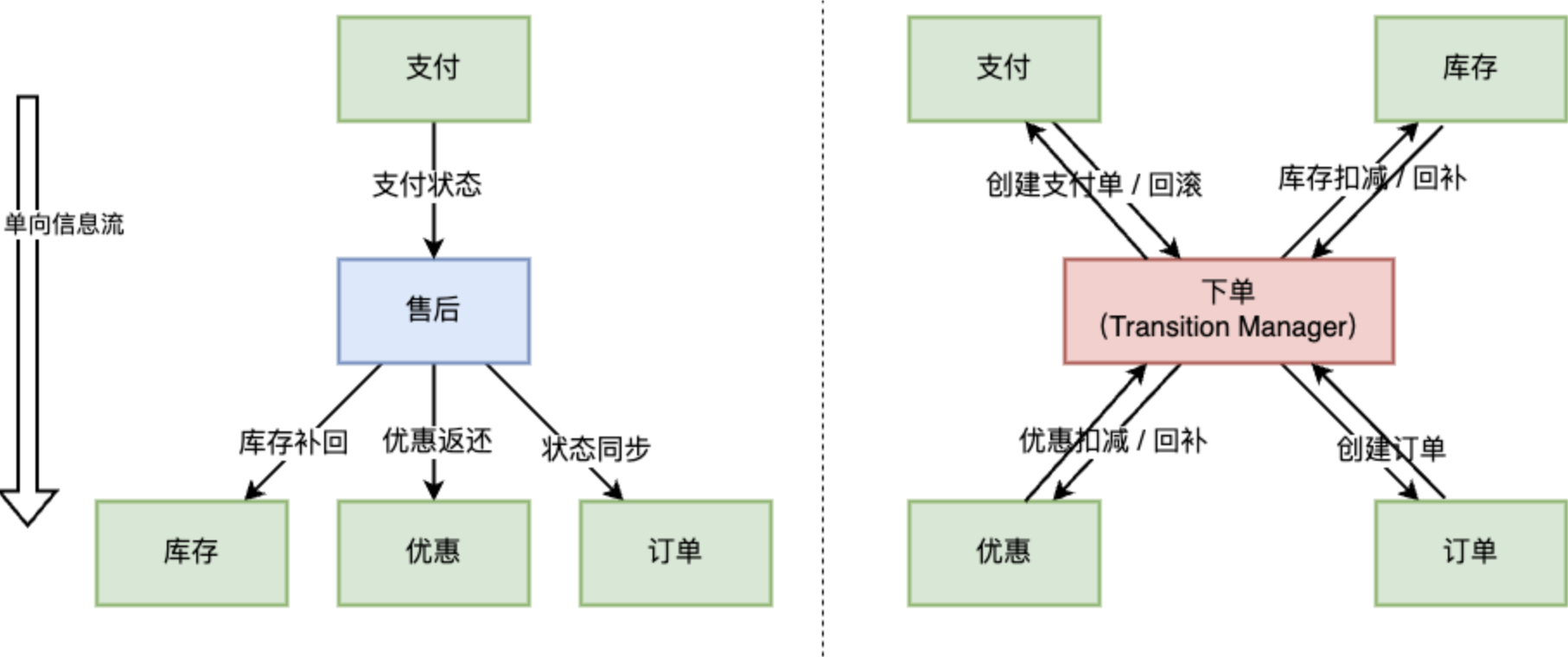
- 性能 & 高可用:分布式系统有 CAP 理论,如果需要高可用性,必然需要牺牲强一致性,选择最终一致性模型。在实际系统中,我们往往会选择 Available:允许系统在面临故障或分区时继续提供服务,即使会产生一些业务上的 bad case。即使是需要强一致性,因为性能的考虑,也一般使用 TCC 而不是 2PC 或者 3PC。(TCC 是一个异步的分布式事务实现。)
处理不一致
当选择用最终一致时,必然会出现一段时间的不一致,在这个不一致的时间窗口里,会存在哪些边际情况?处理的思路又是什么呢?
用户教育、期望管理
在支付成功-回调场景里面,是不一致的一个典型的例子:
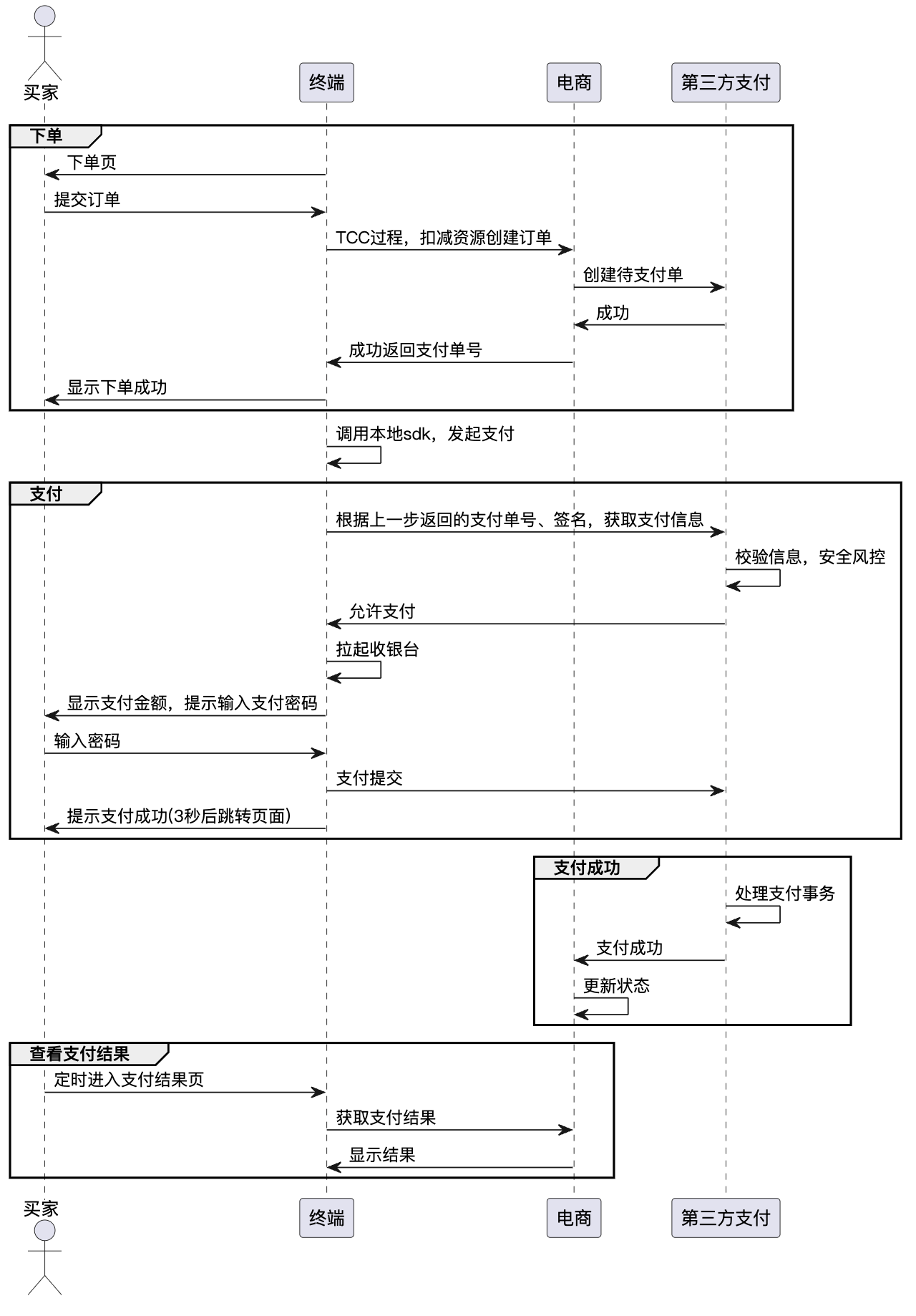
注意支付成功和查看支付结果两步,在时序上是无法保证的,那么就存在不一致 bad case:用户在查看结果时,支付结果处理还未成功。这样的不一致是无法避免的,但可以在工程或交互中做一些优化,例如:1) 跳转时页面刷新后,延迟短的时间重新刷新结果;2) 告知用户存在不一致的情况,让用户自己刷新。虽然听上去不是高大上的解法,但是能处理很多情况。
对于核心资源,隔离到同一领域/单机事务
有时候,不一致的后果不仅是用户体验,而是产生资损,对于这样的后果,思路可以是:对于核心资源,隔离到同一领域/单机事务,利用单机事务实现 ACID。考虑这样的一个边际:
- 用户下单并支付成功。但 callback 由于延迟,未触达电商系统,电商里的订单为“待支付”状态。
- 用户发起关闭订单。
- 订单域发起逆向,调用支付域逆向接口,支付域返回:1) 订单支付中,逆向失败。
这里的思路是支付域通过支付单,逆向支付单的建模,保证整笔资金流的状态/互斥处理是在同一个单机事务中完成的,在调用逆向时,支付域可以保证资金流的正逆向状态是自洽而且一致的:
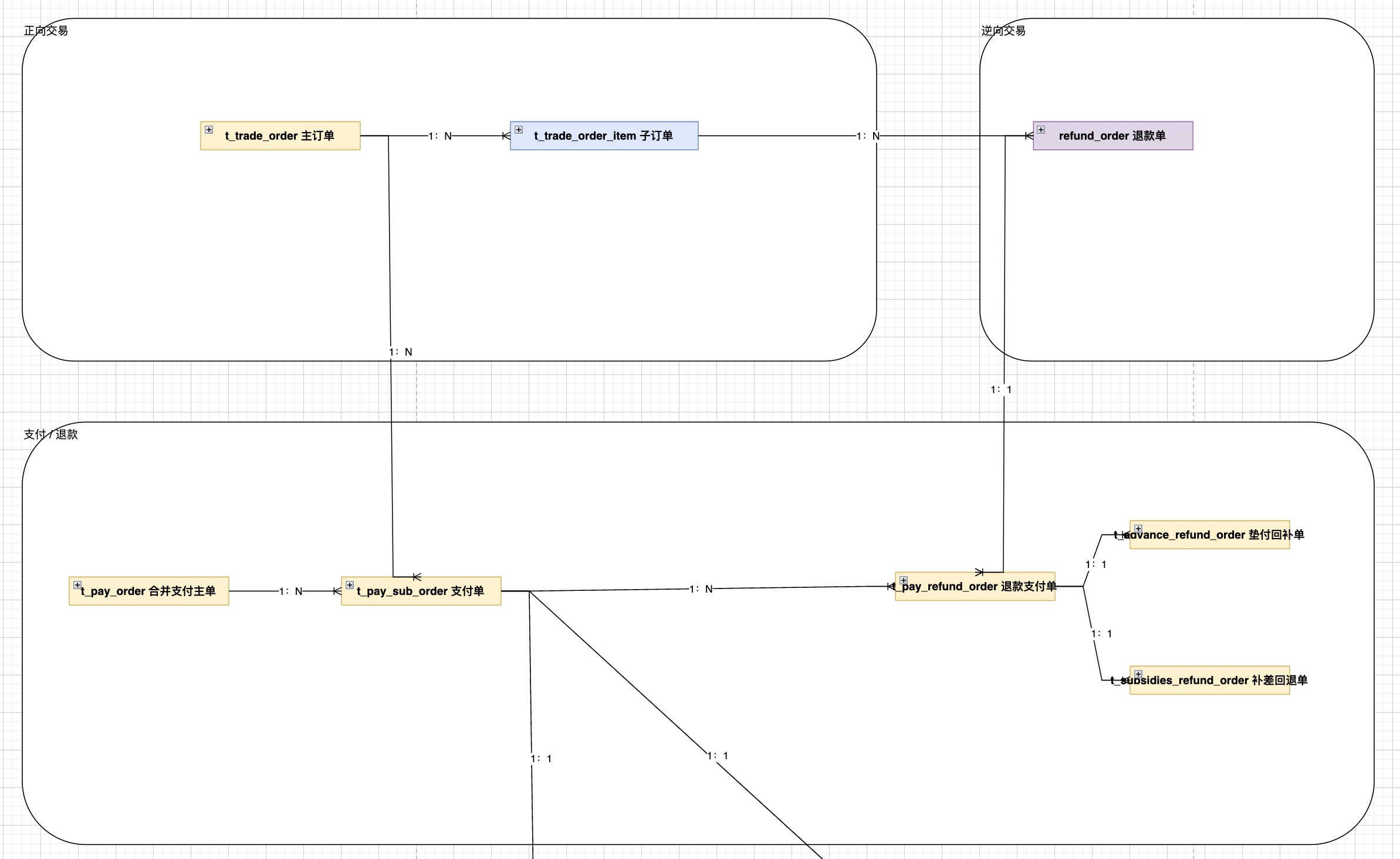
在电商系统里,无论何时,支付域总是资金的信息流上游(它与第三方支付平台交互,并通知给下游),只要通过单机事务的 ACID,保证在上游的信息一致,就避免由于状态不一致的资损。
健壮的最终一致性(状态机+幂等,如何解决大部分的问题)
大部分场景下,通过正确设计的状态机和接口幂等的方法,是解决大部分问题(一致性,状态回滚、甚至资损)的底座。以支付域的订单设计聊聊我的理解。
支付订单的设计,和背后的原理
电商的支付域,依赖第三方支付公司的能力,完成资金流的转移。针对这种第三方支付的场景,一个最简化的状态机可以是这样设计的:
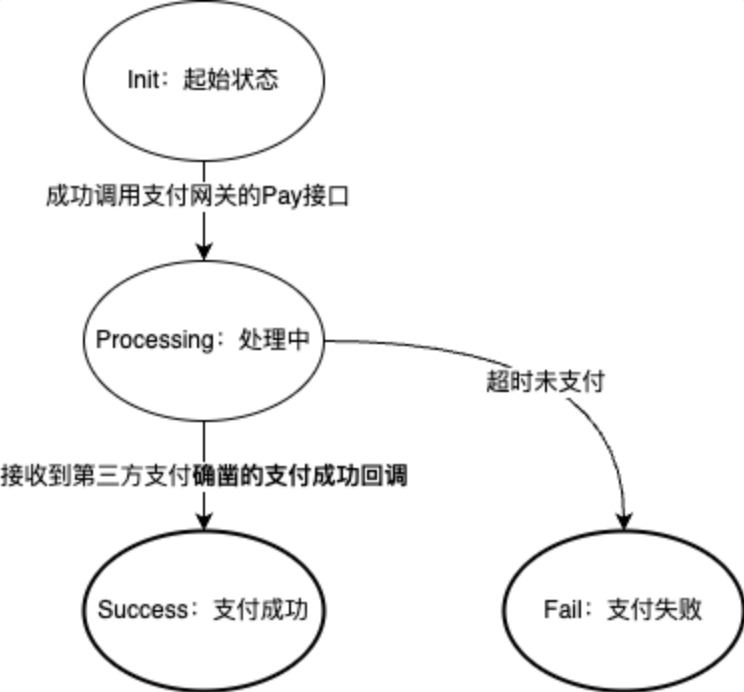
电商支付域需要调用第三方接口,并通过反查/通知的方式获得结果。所以整个状态机抽象为:Init → Processing → Success / Fail。如果你仔细观察,这里其实是一个关于调用异步接口的通用设计。有了健壮的状态机设计后,我们只需要关注哪些动作/接口能推进状态机,这个接口本身是否幂等即可;同时,一个状态机总是应该流转到终态,可以建立补偿任务来推进未完结的状态机,其实就是保证的系统的最终一致,主要上下游保证也幂等,那么可以放心的重试。
下面说说状态机如何设计。
状态机的通用设计
- 每个状态应当不可逆
到达一个状态后,不能回滚到之前的状态,这是非常关键的设计。以上面的支付状态为例,只要支付状态是支付成功,就不允许再更新为 Processing 状态,否则就是资损风险(重复支付)。可以理解为游戏通关的一个保存点:当通关了一个关卡,就不能重玩了。
- 保守推进
什么时候能推进,应该是有严格定义的,以支付域为例,有以下原则:
保守严格定义什么是”支付成功“。这里要有明确的约定支付成功的协议,非这个协议的 Response,都不能推进到 Success。否则:卖家资损。 保守严格定义什么是”支付失败“。在支付的场景里,整个支付过程是需要用户操作,所以只要用户不输入,就不能认为是失败。否则:买家资损。 1. 在支付场景里,没有严格的可以认定为失败的场景,最后只能用超时:超过一定时间未支付,就是失败。 RPC 失败应该怎么处理?不能对错误有任何认定。所有的 RPC 错误都不应该推进状态机。
- 状态推进接口保证幂等
这个很好理解。
再次说说幂等
用比较直观的语言说,幂等的定义是:同一个指令,执行多次的效果和执行一次是一样的。在上面状态机推进的例子中,幂等的实现是状态机本身保证的:在接收到指令 cmd 后,判断当前状态是否这个指令的前缀状态,能否处理这个状态。如果可以,则推进状态机:
if payOrder.Status == Processing {
payOrder.Accept(paySuccessCmd)
}
幂等更通用的实现是两步:
- 定义什么是“同一个指令”,给这个指令一个唯一标识。
- 在接口实现中,记录并判断指令的执行情况:如果这个指令已经执行,下次就直接跳过。
有时候,幂等的实现会更复杂,这个复杂度往往在于究竟如何定义“同一个指令”。比如这样的场景:用户在下单页生成订单,我们用唯一的订单号来标识并处理接口幂等,这个订单号如何生成呢?有几种选择:
- 在后端接口创建订单时生成:这样如果上游重试,会导致重复订单。
- 在前端点击下单按钮时生成:这样有可能因为网络抖动,而发生重复生成。
- 在渲染下单页时就已经生成,这样无论何时点击,都保证了幂等,不会发生重复订单的情况。
显然,3 是更好的方法。可见,幂等应该是端到端的,也就是“同一个指令”应该由指令的发起方定义:只有用户能定义这是同一次下单,而这个唯一标识,应该透传到事务执行的最底层。
Ref
- 《@Software Architecture: The Hard Parts》