
使用DDD重构基础域实战
很多的业务系统都是“干”出来的,意思是产品确定了需求后,开发设计下表层面的数据结构,然后写一系列面向数据库增删改查的接口,通过测试后上线。这种模式在一些项目周期短或者不确定性很大场景下是可行的。但项目很快会暴露问题:代码快速腐化,持续迭代的能力快速下降。从项目开始开发到不可维护的周期,我见过最短的是7-8个月。
先看这样一段代码:
public class TransferController {
private TransferService transferService;
public Result<Boolean> transfer(String targetAccountNumber, BigDecimal amount, HttpSession session) {
Long userId = (Long) session.getAttribute("userId");
return transferService.transfer(userId, targetAccountNumber, amount, "CNY");
}
}
public class TransferServiceImpl implements TransferService {
private static final String TOPIC_AUDIT_LOG = "TOPIC_AUDIT_LOG";
private AccountMapper accountDAO;
private KafkaTemplate<String, String> kafkaTemplate;
private YahooForexService yahooForex;
@Override
public Result<Boolean> transfer(Long sourceUserId, String targetAccountNumber, BigDecimal targetAmount, String targetCurrency) {
// 1. 从数据库读取数据,忽略所有校验逻辑如账号是否存在等
AccountDO sourceAccountDO = accountDAO.selectByUserId(sourceUserId);
AccountDO targetAccountDO = accountDAO.selectByAccountNumber(targetAccountNumber);
// 2. 业务参数校验
if (!targetAccountDO.getCurrency().equals(targetCurrency)) {
throw new InvalidCurrencyException();
}
// 3. 获取外部数据,并且包含一定的业务逻辑
// exchange rate = 1 source currency = X target currency
BigDecimal exchangeRate = BigDecimal.ONE;
if (sourceAccountDO.getCurrency().equals(targetCurrency)) {
exchangeRate = yahooForex.getExchangeRate(sourceAccountDO.getCurrency(), targetCurrency);
}
BigDecimal sourceAmount = targetAmount.divide(exchangeRate, RoundingMode.DOWN);
// 4. 业务参数校验
if (sourceAccountDO.getAvailable().compareTo(sourceAmount) < 0) {
throw new InsufficientFundsException();
}
if (sourceAccountDO.getDailyLimit().compareTo(sourceAmount) < 0) {
throw new DailyLimitExceededException();
}
// 5. 计算新值,并且更新字段
BigDecimal newSource = sourceAccountDO.getAvailable().subtract(sourceAmount);
BigDecimal newTarget = targetAccountDO.getAvailable().add(targetAmount);
sourceAccountDO.setAvailable(newSource);
targetAccountDO.setAvailable(newTarget);
// 6. 更新到数据库
accountDAO.update(sourceAccountDO);
accountDAO.update(targetAccountDO);
// 7. 发送审计消息
String message = sourceUserId + "," + targetAccountNumber + "," + targetAmount + "," + targetCurrency;
kafkaTemplate.send(TOPIC_AUDIT_LOG, message);
return Result.success(true);
}
}
上面代码的例子来自这篇文章。是典型的一个Transaction Script。最近接手的一个基础域的repo,项目里全部是这样的过程代码,因为在项目中没有良好建模,而且系统间职责没有划分清楚,项目的维护成本很快变得非常高(新增一个简单的crud接口需要2-3天)。我对它进行重构,将过程记录一下。
重构过程
构建领域对象,寻找聚合,构建领域层
在原来的代码里,全部是贫血模型,并没有领域对象的概念,更惶论聚合的概念。首要的事是要将领域模型显式的抽取出来,并且落在类图上。因为是重构,而不是从0到1的构建一个应用,而且我们负责的域是电商商品域,其实成熟的建模的方案已经很多。所以并没有遵循标准的uml建模步骤(从use case到提取领域概念再到抽取领域模型)。
整个建模过程简化为两步:从结合一些大厂案例,和我们的实际场景,结合当前已有的表结构,梳理出可以支撑当前场景的一套领域对象和聚合。然后进行回测:看看这一套模型能不能支持所有use case,和评估实现复杂度。最后收敛出领域建模:
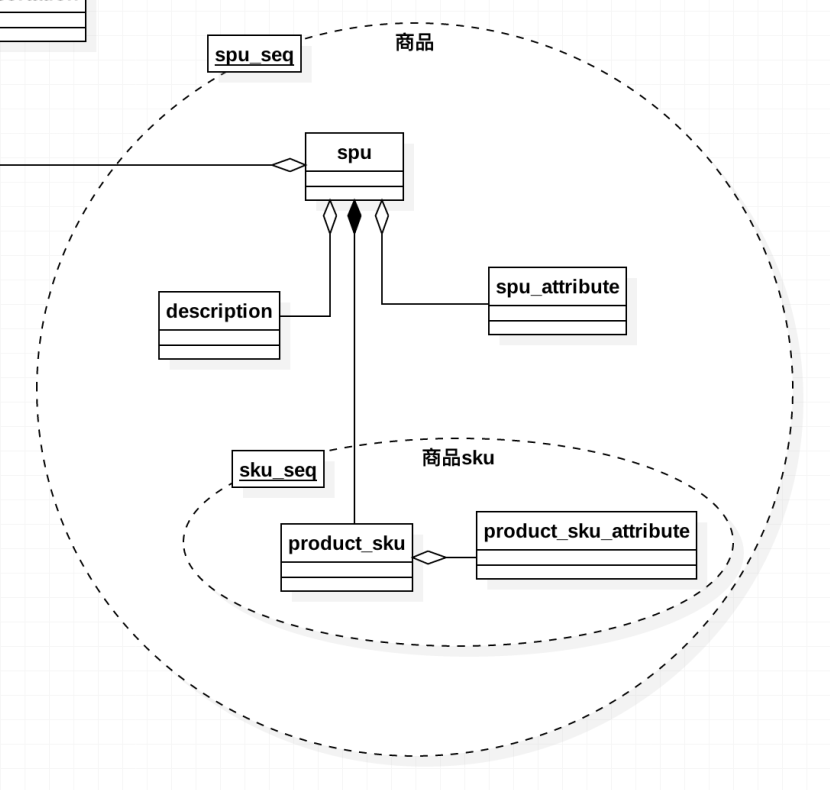
确定聚合
聚合在ddd里是一个有力的抽象,建立好准确的聚合后,事半功倍。我们先来回顾下聚合的定义和约束:
- 定义:一组高度相关的对象,作为一个数据修改的单元
- 一个聚合必须符合:聚合里的实体往往有状态同步;聚合的保存需要原子性,聚合内部的实体脱离了聚合就没有意义。可以参考车和轮子的例子。
一个需要讨论的问题是 商品 和 商品sku 的关系,sku是否属于商品聚合,亦或是有 商品sku 这个聚合?因为在原有代码中,有很多关于sku的操作和接口暴露到域外,所以我们很自然想要单独操作 商品sku 这个领域对象。但最后我们选择的是sku在商品聚合中,原因是考虑到sku实体脱离了 商品 确实没有意义,而且sku和spu有大量的状态关系。
实现领域层代码
当确定领域模型后,在项目内新增相应的entity和aggregate:
实体:
public interface Entity<T> {
T getId();
boolean isNew() {
return getId() != null;
}
}
public class ProductSpu implement Entity<String> {
private String id;
private String name;
private Long salePrice;
// ...
private List<SpuAttribute> attributes;
private Map<String, Property> properties;
}
// ...
聚合:
public interface Aggregate<T> {
/**
* 实现并发乐观锁
*/
Comparable getVersion();
/**
* 聚合根
*/
T getAggrateId();
}
public class Product implement Aggregate<String> {
private String appId;
private String spuSeq;
private long version;
private ProductSpu productSpu;
private List<ProductSku> productSkus;
String getAggrateRoot() {
return productSpu.getId();
}
Long getVersion() {
return version;
}
// 其他业务逻辑
}
寻找domain primitive并显式建模
domain primitive 是在详解 DDD 系列- Domain Primitive一文中提到的概念,原出处来自《Secure By Design》一书(建议看看原文和出处)。我们发现“商品价格”是可以抽取成一个domain primitive,在其内部封装关于价格的一致性约束:
public class ProductPrice {
private double val;
public ProductPrice(double price) {
this.val = price;
this.validate()
}
public void setPrice(double price) {
this.price = price;
this.validatePrice();
}
private void validate() {
if (price < 0) {
throw new ProductInvalidException("product price invalid.");
}
}
private add(ProductPrice val) {
return new ProductPrice(this.val + val);
}
// ... 其他有关价格的操作
}
在 ProductSku 实体里,引用 ProductPrice :
class ProductSku {
// ...
private ProductPrice skuPrice;
}
在提取了entity实体,aggregate聚合,domain primitive之后,我们的关注点就是领域逻辑,而非表的crud。
但还有一步,怎么强制让大家将思维扭转过来,不在事务脚本的思考维度实现接口和需求?答案在下一点:repository。
repository:彻底封装底层存储细节
这一步最重要,它能彻底扭转我们想要写Transaction Script的心智。我们看看类图,对于单一对象而言,整个类和包结构就如下图:
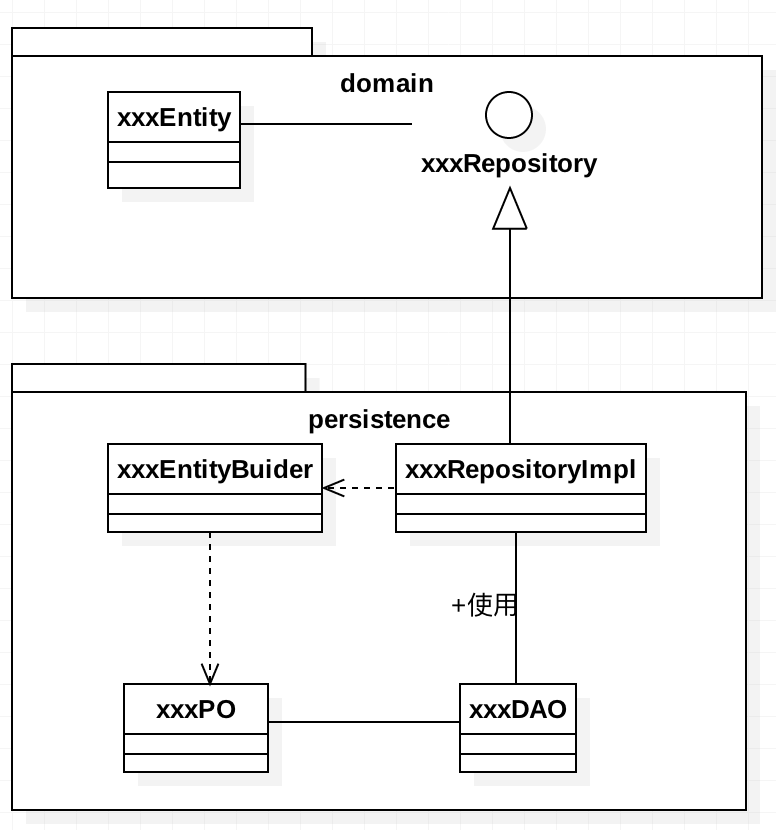
repository类只暴露少量的方法,而且直接返回领域对象,不会返回PO:
public interface Repository<T extends Aggregate<Id>, Id extends Comparable> {
T get(Id id);
void save(T t);
}
而Repository的实现类,是在persistence层的。所以两个包之间的依赖关系是persistence依赖domain层。
你发现什么?这样将entity和PO(persist object)分层后,底层存储细节对领域层彻底不可见了,之前的repository类有很多业务逻辑相关的方法,比如直接更新上下架字段的、直接拼sql删除某个记录的,在这种代码架构下彻底被杜绝。
在这样的代码架构下,我们将程序员的心智从“写事务脚本”扭转过来,所有的接口操作可以描述为这几步:
- 将事务或聚合从repository层获取得到。(注意实体和表结构无耦合,repository和实际存储的实现不耦合)
- 在内存中根据业务规则变更一个或多个实体和聚合的状态
- 使用repositoy将实体持久化到持久层
构建复杂的聚合
对于单个entity而言,因为底层有一个表(PO)和它对应,它的repository是比较好实现的,只要实现好PO -> entity的mapping规则即可:
public class SimpleEntityRepository implements Repository<SimpleEntity, String> {
@Autowired
private SimplePoDao simplePoDao;
@Autowire
private SimpleEntityBuilder builder;
@Override
public SimpleEntity get(String s) {
return builder.toEntity(simplePoDao.get(s));
}
//...
}
而对于复杂的聚合,会在持久层对应多个po和表,这时repository的方法参数还是返回聚合根对象,但在repositoryImpl实现的时候,需要处理更复杂的构建逻辑:
public class ProductRepositoryImpl implements ProductRepository {
@Autowired
private SpuDao spuDao;
@Autowire
private SpuAttributeDao spuAttributeDao;
@Autowire
private SkuDao skuDao;
@Autowire
private ProductBuilder builder;
@Override
public Product get(String productId) {
SpuPo spuPo = spuDao.get(productId);
List<SkuPo> skuPos = spuDao.getList(productId);
List<SpuAttributePo> attributes = spuAttributeDao.getList(productId);
// ...其他po
return builder.builder().spu(spuPo).skuPos(skuPos).attributes(attributes).build();
}
//...
}
有业务大部分场景中,其实并不需要构建完整聚合(一个完整的商品聚合涉及到7-8张表),我们当前的设计是,按需查找,但还是一个一个完整的商品聚合对象返回给领域层。
public interface ProductRepository extends Repository<Product, String> {
Product getSelective(String id, List<ProductDomain> domains);
}
如何保存
聚合的保存需要原子性,也就是repository接口必须暴露保存整个聚合的一个接口,领域层执行完业务逻辑好,调用这个方法原子的保存整个聚合信息。但是大部分业务场景不会修改这个聚合下所有实体的状态,真正需要写库的只有几个记录,那么save的时候应该如何处理?
我的做法是在领域层获得到聚合之后,先在内存里保存一份修改前的快照,在调用save方法时,将修改前和最新的聚合都传入,让repository层做diff:
public class ProductRepositoryImpl implements ProductRepository {
@Override
@Transaction(rollback = Exception.class)
public void save(Product product, Product origin) {
if (update.isNew()) {
insert(product);
return;
}
if (product.getProductSpu() != null) {
if (differ.needSave(product.getProductSpu(), origin.getProductSpu())) {
save(builder.toPo(product.getProductSpu()));
}
}
// 保存其他entity
}
//...
}
differ比较两个实体是否一致,同时也可获取不一样的字段(如果需要有修改记录,可以通过这个方法动态获取),实现上也比较简单:
public class ModelDiffer<T extends Entity> {
public boolean needSave(T origin, T update) {
Objects.requireNonNull(update);
return !isModelEquals(origin, update);
}
public boolean isModelEquals(T origin, T update) {
Objects.requireNonNull(update);
return origin != null && update.equals(origin);
}
public List<DiffProperty> getDiffProperties(T origin, T update) {
Objects.requireNonNull(update);
ArrayList<DiffProperty> results = new ArrayList<>();
if (origin == null) {
results.add(new DiffProperty("CREATION", update.toJsonString(), ""));
return results;
}
Class clazz = update.getClass();
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
try {
field.setAccessible(true);
Column column = field.getAnnotation(Column.class);
if (column == null) {
continue;
}
String fieldName = column.name();
if ("id".equals(fieldName) || "created_at".equals(fieldName) || "updated_at".equals(fieldName)) {
continue;
}
String toValue = getValueFrom(field, fieldName, update);
String fromValue = getValueFrom(field, fieldName, origin);
if (toValue == null || toValue.equals(fromValue)) {
continue;
}
results.add(new DiffProperty(fieldName, fromValue, toValue));
} catch (Exception e) {
logger.error("getDiffProperties error", e);
} finally {
field.setAccessible(false);
}
}
return results;
}
private String getValueFrom(Field field, String fieldName, Object object) {
Object value = null;
try {
value = field.get(object);
} catch (IllegalAccessException e) {
logger.error(String.format("getDiffProperties error: 取字段[%s]失败", fieldName), e);
}
if (value == null) {
return null;
} else if (value instanceof BigDecimal) {
return ((BigDecimal) value).setScale(13, BigDecimal.ROUND_HALF_UP).toString();
} else {
return value.toString();
}
}
}
在看了这篇文章,发现一个更好的实践,就是将snapshot保存到threadlocal里,彻底对上层domain层透明,当然也是可行的办法。
应用架构
完成领域层和持久化层的搭建后,我们的应用架构已经梳理出来。我以商品聚合为例,用类图的话表达如下:
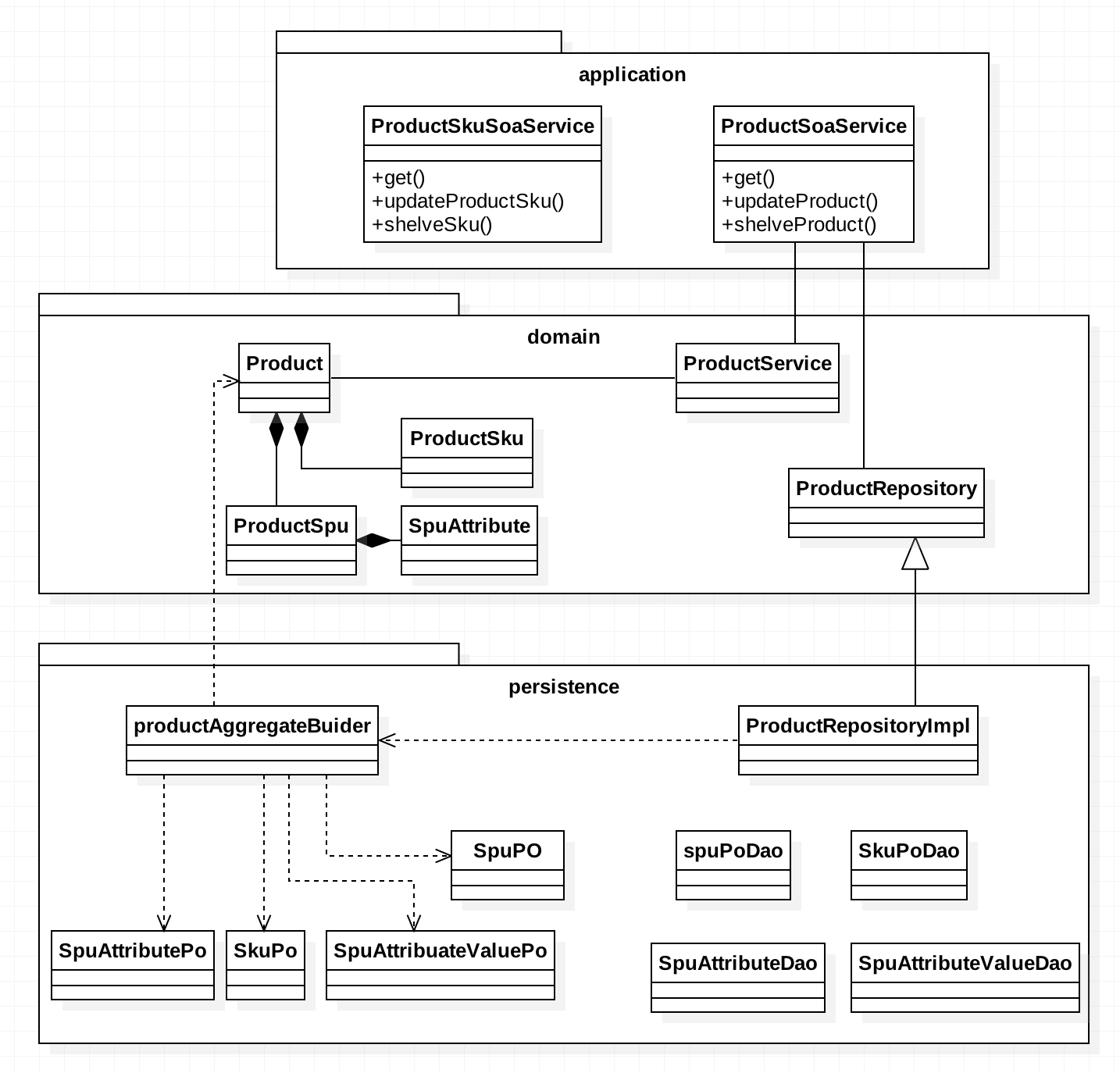
用一个比较抽象的六边形图的话,是这样的:
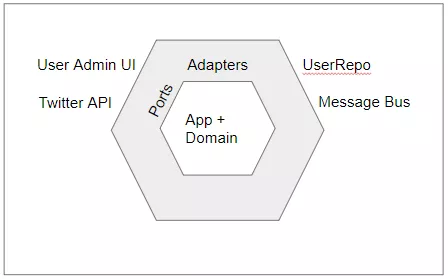
你已经看到,这个应用架构的核心思想是屏蔽所有外部依赖,包括持久层的实现、上下游依赖、中间件依赖(redis、mq)。从而获得一个稳定的领域层。
定规范
在搭起来项目架构后,应用层、持久层和领域层的职责和隔离已经在代码里显式的表达出来。还需要确定聚合之间的使用规范,领域服务的规范,指导组里的同学后续的开发,确保领域层的核心逻辑腐化速度降到最低。
一共有这几点:
- 聚合aggregate
- 聚合内部的实体,只能通过聚合根引用。不允许直接构建这个实体对象。举个例子,如果“商品属性”显然属于商品聚合,所以获取属性时,必须通过
productRepository.getProduct获取product的聚合根对象,然后通过product.getAttribute获取属性。 - 对于状态字段,避免public setter,封装状态变更。一些重要的状态字段,涉及到实体本身的一致性约束,这些字段不允许直接通过setter修改,而必须通过在聚合类暴露有业务语义的方法,比如,
上下架、价格修改等。一致性约束在方法里实现。 - 通过聚合处理聚合里面多个实体的一致性状态。这个是使用聚合的最大好处,多个子实体之间的状态一致性需要聚合根来保障。
- 聚合暴露的方法只允许修改它自己本身,聚合不允许直接直接修改其他聚合的状态。如果涉及到多个聚合的状态修改,必须通过domain service完成。
- 聚合内部的实体,只能通过聚合根引用。不允许直接构建这个实体对象。举个例子,如果“商品属性”显然属于商品聚合,所以获取属性时,必须通过
- 领域服务domain service
- 领域服务本身不会调用repository,不负责实体和聚合的持久化,这部分工作交给应用层,完成。
- 领域服务负责协调多个聚合或实体之间的相互交互和状态变更。
规范定好后,看看我们写代码的mind set有什么不一样,这是一个重构之后,一个接口的典型代码(当然有不少简化):
public class ProductSoaService {
ProductDTO getProduct(GetProductRequest request) {
Product product = repository.get(request.getId())
return productDtoTransformer.transform(product);
}
Result updateProduct(UpdateProductRequest request) {
ProductSaveParam saveParam = transformToParam(request);
String productId = request.getProductId();
// 获取聚合
Product product = repository.get(productId);
if (product == null) {
// ...
}
Product origin = BeanUtil.copyBean(product);
// 根据入参param,在内存中更新聚合实体
productCoreService.updateProduct(saveParam, product);
// 聚合的规则校验
if (!Validation.validate(product)) {
throw new Exception("校验不通过");
}
// 调用持久层的方法,保存聚合
repository.save(product, origin);
// 发布领域事件
Publisher.publish(PRODUCT_UPDATE_EVENT, product)
}
}
可以看见在重构之后,一个接口的流程就变成了:
- 获取聚合或实体
- 通过domain service,根据业务规则变更一个或多个实体和聚合的状态
- 校验一致性约束(validation)
- 执行持久化,保存聚合
- 发布领域事件
迁移步骤
由于不是重写项目,而是在原来的项目上重构代码,所以更需要小心,如果在过程中改动到原来的实现逻辑,就有可能影响线上环境。我们采用的方法是从上到下都新写一套,包括application-domain-repository,所以会有v2的domainService和repository,包括对外接口层,而原来的老代码保持现状,这样最大的好处是老代码不受影响,而且可以通过切流,逐步迁移,风险可控。
切流
在原来接口里会加入开关,打开开关时,流量走新的V2接口,并通过adapter层转换出参入参,实现逐个接口的切流。
验证
在本次迁移,由于不涉及数据迁移,只需要保证代码逻辑保持一致,最终的方案是通过unit test保证迁移前后的逻辑一致,如果是涉及数据迁移的重构,那么必不可少的过程就是数据双写,比对数据准确,然后再逐步的迁移接口流量。