
分布式系统case by case - google file system(GFS)
google file system是15年前(2003)google发布的一个分布式文件系统论文,这篇论文可以说是分布式系统的入门经典。google应该是全球最早遇到如此复杂的分布式技术难题的公司。gfs是其中一个难题的解决方案:超大规模的,可靠的文件存储。看gfs的这篇论文,可以看到google的牛逼的大神们是怎样思考和工作的:遇到一个问题,做假设,设计系统,完成工程,最后将整个过程和经验输出为论文。
workload
GFS是Google为其内部应用设计的分布式存储系统。google内部对文件系统的访问特点如下:
- 数据集庞大,数据总量和单个文件都比较大,如应用常常产生数GB大小的单个文件;
- 数据访问特点多为顺序访问,比较常见的场景是数据分析,应用程序会顺序遍历数据文件,产生顺序读行为;
- 多客户端 并发追加 场景很常见,极少有 随机写 行为;
- 一次写入,多次读取,例如互联网上的网页存储。
其中,第三点是最重要的,一些架构上,feature上的取舍都是对它的权衡。我们接下来就会看到。
architecture
gfs的架构图如下:
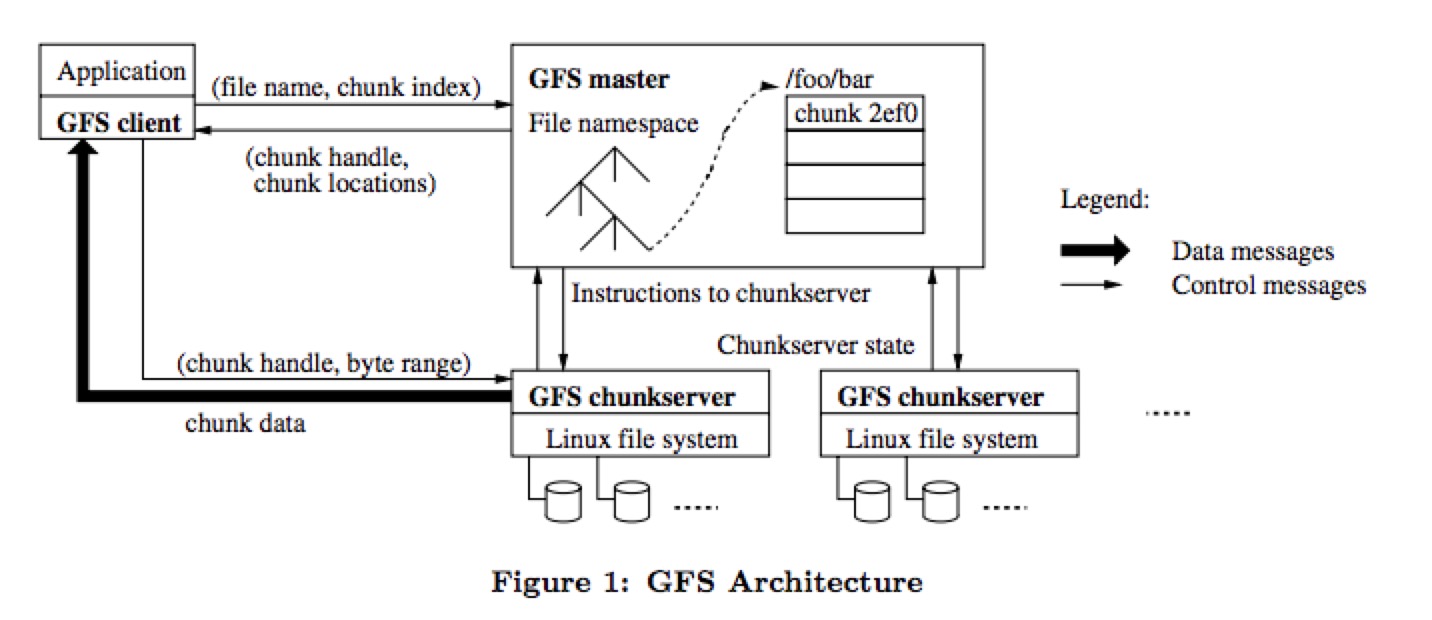
整个gfs的集群可分为:一个master,多个chunkservers。master和chunkserver都有可能和client直接联系。
- master:存储系统元数据信息,主要包括namespace、文件chunk信息以及chunk多副本位置信息。Master是系统的中心节点,所有客户端的元数据访问,如列举目录下文件,获取文件属性等操作都是直接访问Master。
在介绍chunkserver之前,先说说chunk的概念:在gfs里,一个大的文件会分为多个chunks。一个chunk的大小是固定的,是64mb,一个chunk是数据复制的基本单位。当client要读一个文件的时候,在send request的时候其实会把file name和chunk index发给master。master会将每个chunk index所在的chunkserver返回给client。
- chunkserver:是文件chunk的存储位置。每个数据节点挂载多个磁盘设备并将其格式化为本地文件系统(如XFS)。将客户端写入数据以Chunk为单位存储,存储形式为本地文件。
master fault tolerant
如上所述,gfs的架构是single master的,那么会引起两个问题:1. 单点故障,2. master读写瓶颈。看看gfs是怎么解决这两个问题。
客户端直接访问chunkserver,最小化client和master的交互
用一次简单的read操作中,client、master、chunkserver三者间的交互说明这个问题。
- client知道他要读取的文件名和文件大小。
- client将文件名+文件大小转换成文件名+chunk index请求master。(由于chunk size是确定的,client可以根据文件大小确定chunk index。比如:一个640mb的文件,要读取后一半的数据,那么chunk index就是 6 - 10。)
- master接收到文件名和chunk index后,在内存中的metadata中找到对应的chunk所在的chunkserver的hostname,返回给client。
- 这时master的工作已经完成,client可以直接和chunkserver交互并读取文件。
这样,在一次read操作中,client和master只有一次交互。为进一步减少对master的请求,client还会将master返回的信息cache起来。client再次请求相同文件的时候,不需要和master交互。
master高可用
该如何解决master的单点问题呢?或者说,master的高可用,该怎么做?答案是:冗余。
master存储metadata,所有对metadata的修改都是有操作日志的。操作日志对master的高可用起着重要的作用:一旦master挂了,只要operation log没丢,可以根据它,反向计算出master的state。而冗余的关键就在冗余操作日志,将操作日志多实例备份,在master挂了的时候,使用backup,读取operation log,恢复状态,继续提供服务。
在这点设计上,gfs的做法是,保证一致性,一定程度的牺牲可用性:每次client和master的交互,gfs会同步的将操作日志记录在本地,并发送到backup节点,操作日志写入到本地和远程的磁盘都成功,才会返回给客户端。
consistency model
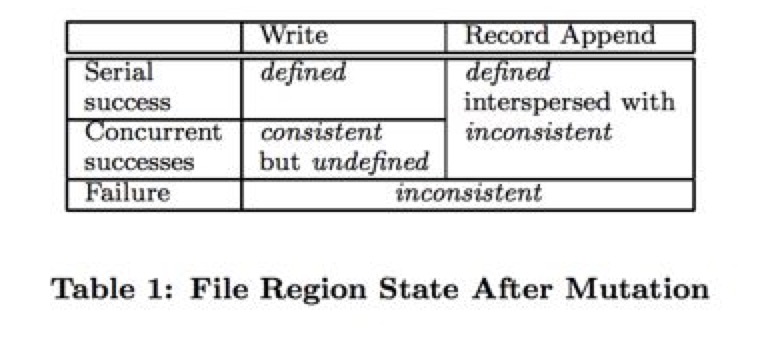
如上图,gfs对外提供的一致性保证中,提供了4种语义。分别是:
- consistent:所有client都能读到相同的data
- defined:是consistent的而且都能完整的读到最新的写入
- inconsistent and also undefined:不同的client在不同的时间看到不同的内容。(我的理解是:这个状态下的data已经损坏)
- undefined but consistent:所有client都能读到相同的data,但data可能是错误的(就是发生了并发写的问题导致data错误)
在上图中,可以看到两个column:write和record append。其中,write的情况很容易理解,无非是串行写还是并发写,如果是并发写,则gfs不保证数据是defined的。
record append是gfs的核心feature,它保证多client并发的以record append方式写入的数据是defined的。我们下面会看到,这点保证是如何实现的。
data flow
再说record append之前,说一下一个普通的写入操作,client、master、chunkserver三者的交互过程。
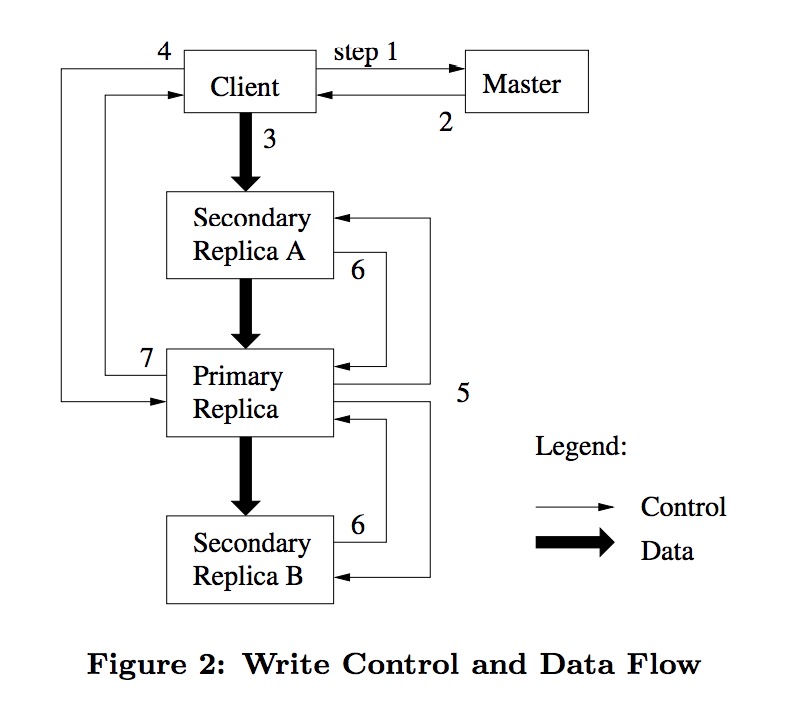
数据的写入可分为7步:
- 客户端向Master查询待写入的chunk的副本信息,
- Master返回副本列表,第一项为主副本,即当前持有租约的副本;
- 客户端向多副本推送待写入数据,这里的推送是指将数据发送至chunk多副本,chunkserver会缓存这些数据,此时数据并不落盘;
- 客户端向主副本发起Sync请求;
- 主副本将数据写入本地的同时通知其他副本将数据写入各自节点,此时数据方才落盘;
- 主副本等待所有从副本的sync响应;
- 主副本给客户端返回写入成功响应
record append
gfs定义一种原子操作:一次写入的数据必须是原子性的添加到文件 结尾(record append 操作必须写入文件尾部,不支持随机写的record append操作)。这样的操作称为record append。这样的操作提供一种一致性保证:即使是多个clients同时执行record append操作,即使完全没有任何的同步机制,也不会出现并发问题。
下面来说说record append 的实现。
record append 和普通的write在流程上基本一致,不同点在于:
- 写入的chunk index不再由client指定,client只能指定data要写入到文件尾部。gfs会选择data最终落在哪个chunk上。
- 单次写入的data是有大小限制的(想想看,如果不加限制,根本不可能保证原子性和性能上的可用):单次写入最大体积是1/4个chunk size,也就是16mb。
- 在流程上,record append有额外的一步:在真正写入磁盘前,作为primary的chunk server会检查:这一次写入时候会超过当前chunk的最大容量,如果否,正常写入;如果是,会:
- 在当前chunk上,用添加padding的方式将它填满。(也就是不让其他客户端再写入这个chunk了)。
- 给client返回失败,让客户端重试。
gfs通过这几点保证,一次写入的data会写到单一的chunk上,从而保证record append的一致性保证。
当然,这种操作会引入新的问题:
- 在上面的第三点,如果一次写入失败,那么padding的数据其实是stale data,这样的case该如何处理?
- record append提供的是最少一次(at least once)的原子写入,也就是,有可能有多次成功的写入,导致产生重复的数据,这样的case该如何检测和处理?
留待读者在论文本身找到答案。 :)
参考
- http://nil.csail.mit.edu/6.824/2017/papers/gfs.pdf
- http://nil.csail.mit.edu/6.824/2017/notes/l-gfs-short.txt
- http://www.cs.cornell.edu/courses/cs6464/2009sp/lectures/15-gfs.pdf
- https://zhuanlan.zhihu.com/p/28155582
- http://pages.cs.wisc.edu/~remzi/Classes/537/Fall2008/Notes/gfs.pdf